오픈소스 LLM모델로 유명한 Llama 시리즈가 몇 달 전 3.1을 출시했는데 더욱 가벼워진 3.2로 돌아왔습니다.
3.2 모델은 경량화된 1B, 3B 모델을 포함하여 개인 사용자의 접근성을 넓혔습니다.

11B, 90B 모델은 멀티모달에 특화되어있지만 본 포스팅에서는 경량화된 1B, 3B의 이야기만 다룹니다.
멀티모달에 관심있으신 분은 사진을 클릭해서 내용을 확인하세요
Download models를 누르면

이러한 화면이 나타나는데, 내용을 모두 입력하면 심사를 거친 뒤 48시간 동안 사용가능한 코드를 발급받게 됩니다.
이후 과정은 간단합니다. 신청을 하면 자세히 알려주는데 대략의 순서는 다음과 같습니다.
1. Llama stack 설치
2. 원하는 버전 선택
3. 발급받은 키 입력
위 과정을 거치면 사용자 폴더의. llama 폴더에 체크포인트 폴더가 생성되고 그 안에 설치한 내용이 들어가 있습니다.
Llama 3.2 -1b-instruct를 설치해 보았는데 이렇게 4개로 구성이 되어있습니다. 각 파일을 대략적으로 살펴보면
1. consolidated.00.pth (가중치 파일)
- 역할: 이 파일은 모델의 가중치(Weights)를 저장합니다. 모델의 학습된 매개변수들이 저장된 파일입니다.
- 설명: 모델이 학습하는 과정에서 학습된 가중치가 저장되며, 모델의 아키텍처에 따라 이 가중치가 다양한 층(layer)에 적용됩니다. 이 파일을 로드하면 학습된 모델의 성능을 그대로 사용할 수 있습니다.
- 사용 방법: torch.load()로 가중치를 로드한 후, 모델에 이 가중치를 적용합니다.
2. tokenizer.model (토크나이저 파일)
- 역할: SentencePiece 토크나이저 파일로, 텍스트를 모델이 이해할 수 있는 토큰(token) 단위로 변환해 주는 역할을 합니다.
- 설명: LLaMA 모델은 SentencePiece를 사용하여 텍스트를 토큰화합니다. 이 파일은 텍스트를 처리하는 데 필요한 규칙(어휘, 토큰화 방식 등)을 포함하고 있습니다. 입력 텍스트를 토큰으로 변환하고, 모델이 생성한 토큰을 다시 텍스트로 디코딩하는 데 사용됩니다.
- 사용 방법: LlamaTokenizerFast 또는 SentencePieceProcessor를 사용하여 로드하고, 입력 텍스트를 토큰화하거나 토큰을 디코딩할 때 사용됩니다.
3. params (모델 하이퍼파라미터 정보)
- 역할: 모델의 하이퍼파라미터 정보가 저장된 파일입니다. 모델의 크기, 레이어 수, 히든 유닛의 수 등과 같은 설정 값들이 포함되어 있습니다.
- 설명: 모델을 로드할 때, 해당 파라미터 값에 맞춰 모델이 생성되도록 도와줍니다. 이 파일을 통해 모델의 아키텍처에 대한 기본 정보가 제공됩니다.
- 사용 방법: 모델을 초기화하거나 가중치를 로드할 때 참고되는 설정 파일입니다.
4. checklist.chk (체크포인트 파일)
- 역할: 이 파일은 체크포인트 파일로, 모델 훈련의 상태나 특정 시점에서의 정보들을 기록합니다.
- 설명: 모델 훈련 중간에 생성된 체크포인트 파일로, 모델의 훈련을 이어서 진행하거나 특정 시점에서 모델을 복원할 때 사용될 수 있습니다. 훈련 과정 중 저장된 상태나 가중치의 유효성을 검증하는 역할을 할 수 있습니다.
- 사용 방법: 훈련 중간에 중단된 상태에서 훈련을 다시 시작할 때 사용될 수 있지만, LLaMA 모델을 단순히 로드해 사용하려는 경우에는 크게 중요한 파일은 아닐 수 있습니다.
크기는 대략 2.5 GB입니다.
Llama 3.1- 8b 모델이 약 4.7GB 인 것을 생각하면 약 50% 날씬해졌습니다.

1b 모델과 3b 모델의 차이를 벤치마크를 통해 확인할 수 있습니다.
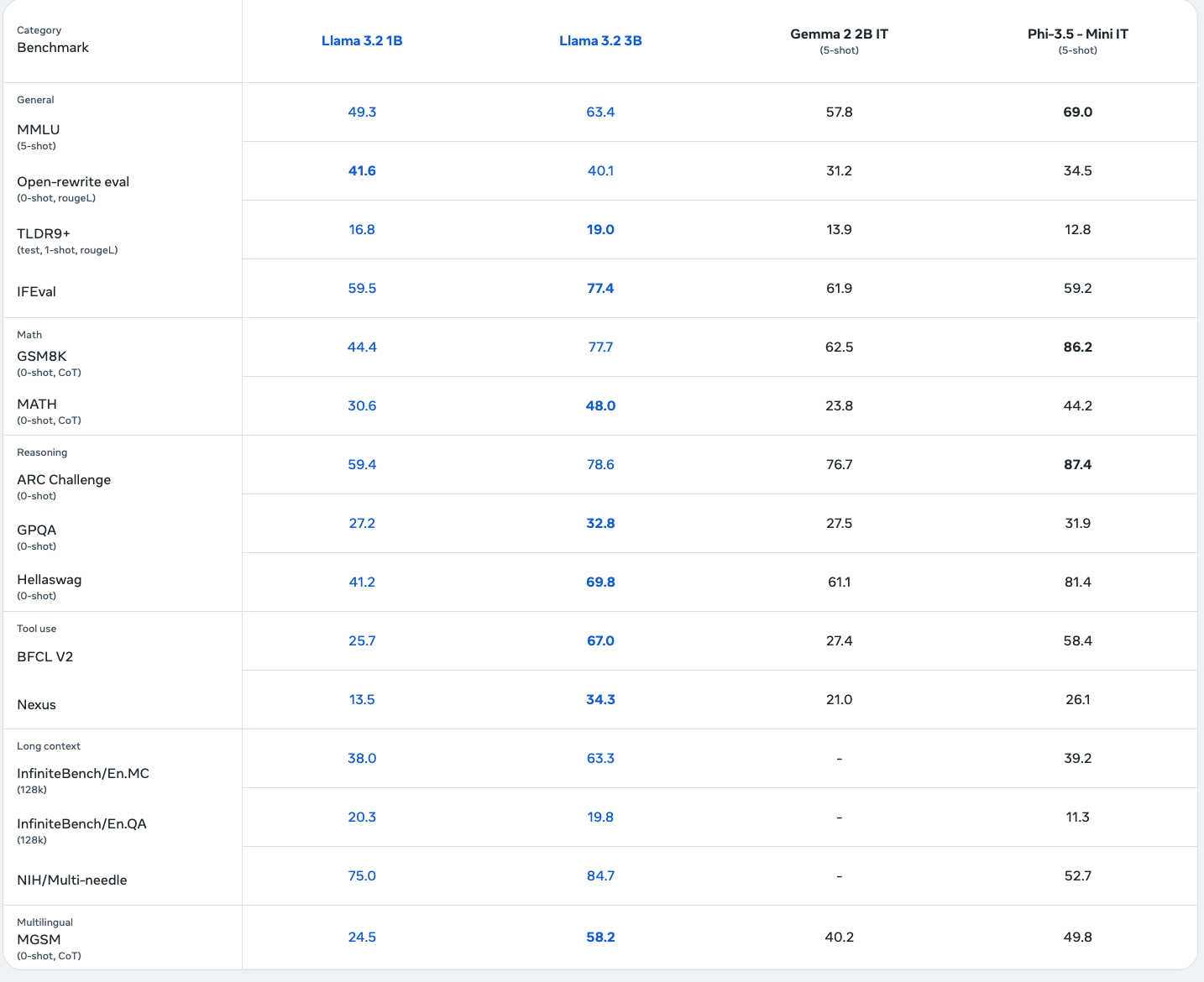
다만 Llama의 한국어 성능에 약한 모습이 있는데 이를 해결하기 위한 Bllossom팀의 노력이 있었습니다.
2024. 10. 08에 Bllossom 팀에서 한국어를 강화하였습니다. 해당 모델에 관심이 있거나 자세한 정보가 궁금하신 분은
허깅페이스에서 정보를 확인할 수 있습니다.
Bllossom팀의 소개글입니다.
저희 Bllossom 팀에서 Bllossom-3B 모델을 공개합니다.
llama3.2-3B가 나왔는데 한국어가 포함 안되었다구?? 이번 Bllossom-3B는 한국어가 지원되지 않는 기본 모델을 한국어-영어로 강화모델입니다.
- 100% full-tuning으로 150GB의 정제된 한국어로 추가 사전학습 되었습니다. (GPU많이 태웠습니다)
- 굉장히 정제된 Instruction Tuning을 진행했습니다.
- 영어 성능을 전혀 손상시키지 않은 완전한 Bilingual 모델입니다.
- LogicKor 기준 5B이하 최고점수를 기록했고 6점 초반대 점수를 보입니다.
- Instruction tuning만 진행했습니다. DPO 등 성능 올릴 방법으로 튜닝해보세요.
- MT-Bench, LogicKor 등 벤치마크 점수를 잘받기 위해 정답데이터를 활용하거나 혹은 벤치마크를 타겟팅 해서 학습하지 않았습니다. (해당 벤치마크 타게팅해서 학습하면 8점도 나옵니다...)
언제나 그랬듯 해당 모델은 상업적 이용이 가능합니다.
1. Bllossom은 AAAI2024, NAACL2024, LREC-COLING2024 (구두) 발표되었습니다.
2. 좋은 언어모델 계속 업데이트 하겠습니다!! 한국어 강화를위해 공동 연구하실분(특히논문) 언제든 환영합니다!!
'소식 > 기술 소식' 카테고리의 다른 글
| 멀티 에이전트 시스템- SWARM (5) | 2024.10.21 |
|---|---|
| F5 TTS 사용법 (1) | 2024.10.16 |