
OpenScholar
과학 문헌 검색과 요약의 새로운 길
목차
배경 및 소개
스팩
동작원리
사용 방법
심화
OpenScholar의 탄생 배경
과학 연구는 매년 방대한 양의 논문이 발표되면서 최신 정보를 빠르게 파악하고 활용하는 것이 점점 더 어려워지고 있습니다. 기존의 언어모델(Large Language Model, LLM)은 과학적 정보를 요약하거나 인용하는 데 많은 한계를 보였습니다. 특히, 인용 오류(hallucination)와 최신 논문을 반영하지 못하는 문제는 연구자들에게 실질적인 어려움을 안겨주었습니다.
이를 해결하기 위해 OpenScholar가 등장했습니다. OpenScholar는 검색 증강 언어 모델(Retrieval-Augmented Language Model)을 기반으로, 방대한 과학 문헌 데이터에서 실시간으로 정보를 검색하고, 정확한 인용을 포함한 답변을 생성하는 데 특화된 모델입니다.
제작사와 출시 시기
OpenScholar는 워싱턴 대학교(University of Washington), Meta, 그리고 Allen Institute for AI의 공동 연구로 개발되었습니다. 이 프로젝트는 2024년 11월, 학술 논문 및 오픈 소스로 정식 공개되었습니다. 현재 GitHub를 통해 코드와 데이터셋이 제공되며, 누구나 활용할 수 있습니다.
• 프로젝트 GitHub: OpenScholar
OpenScholar 스팩
OpenScholar의 기술적 구성 요소 및 학습 방식
1. OpenScholar의 언어 모델
OpenScholar는 OpenScholar-8B라는 언어 모델을 중심으로 설계되었습니다. 이 모델은 다음과 같은 기술적 특징을 가집니다:
• 모델 크기: 80억 개의 매개변수를 가진 중간 규모의 언어 모델.
• 언어 모델 기반: OpenScholar는 Llama 3.1과 같은 최신 언어 모델을 기반으로 학습되었으며, 과학 분야의 특화된 데이터를 활용하여 추가적으로 미세 조정되었습니다.
• 학습 데이터:
• OpenScholar는 45백만 편의 오픈 액세스 논문에서 생성된 234백만 개의 텍스트 블록을 활용.
• 데이터셋은 Semantic Scholar의 peS2o 데이터셋(v3)을 기반으로 구축.
• 각 논문은 제목과 본문을 결합하여 250단어로 나누어 처리.
2. 데이터스토어 (OPENSCHOLAR-DATASTORE, OSDS)
OpenScholar는 대규모 데이터스토어를 활용하여 정보를 검색하고 생성합니다.
• 데이터셋 규모:
• 총 45백만 편의 논문과 234백만 개의 텍스트 블록 포함.
• 다양한 학문 분야(컴퓨터 과학, 생물의학, 물리학, 신경과학)를 아우르는 데이터셋.
• 특징:
• 데이터는 논문의 제목과 250단어의 본문 블록으로 나뉘어 저장.
• 각 텍스트 블록은 밀집 표현(embedding)으로 전처리되어 검색 효율성을 극대화.
3. 검색 시스템
OpenScholar는 효율적인 검색을 위해 두 단계 검색 시스템을 사용합니다.
1. Bi-Encoder Retriever (θbi):
• Dense Passage Retriever 기반.
• 질문과 문단을 개별적으로 밀집 벡터로 변환하여 가장 관련성이 높은 텍스트를 선택.
• Contriever 모델을 peS2o 데이터셋에 특화하여 추가 학습.
2. Cross-Encoder Reranker (θcross):
• Bi-Encoder로 검색된 텍스트를 다시 평가하여 최종적으로 상위 N개의 문단 선택.
• Llama 3.1 기반 모델을 활용하여 각 문단과 질문 간의 관련성을 스코어링.
• 긍정(45점), 중립(3점), 부정(12점)으로 점수를 분류하여 학습.
4. 학습 방식
OpenScholar는 학습 단계에서 고품질 데이터 생성과 피드백 기반 개선(self-feedback) 방식을 활용합니다.
1. 고품질 데이터 생성:
• 문헌 기반 질의 생성:
• 논문의 초록에서 문헌 리뷰 질문을 자동으로 생성.
• 피드백 및 응답 데이터 생성:
• 초기 답변을 생성한 후, 모델이 스스로 피드백을 작성하고 이를 반영하여 최종 답변을 개선.
• 데이터 필터링:
• 생성된 데이터를 품질 기준(정확성, 조직력 등)으로 평가하고, 4.5점 이상의 데이터만 사용.
2. 다단계 학습 과정:
• 학습 데이터: 답변 생성(x → y), 피드백 생성(y0 → F), 피드백 반영(yt-1, ft → yt) 데이터 포함.
• 데이터 혼합: 과학 분야 데이터와 일반 도메인 데이터를 50:50 비율로 혼합.
• 모델 학습:
• OpenScholar-8B는 130,000개의 학습 인스턴스를 2에포크 동안 학습.
5. 성능 평가
OpenScholar는 자체 벤치마크 ScholarQABench를 활용하여 모델 성능을 평가했습니다.
• 벤치마크 데이터:
• 2,967개의 과학적 질문과 208개의 전문가 답변 포함.
• 4개 분야(컴퓨터 과학, 생물의학, 물리학, 신경과학)에서 설계.
• 평가 메트릭:
• 정확성(Correctness), 인용 정확도(Citation Accuracy), 커버리지(Coverage), 조직력(Organization).
• 인용 오류 비율: OpenScholar-8B는 **0%**의 오류를 기록, GPT4o의 78-90%에 비해 우수한 성능.

6. OpenScholar의 혁신적 특징
1. 검색 증강 및 피드백 기반 학습:
• 검색된 데이터를 기반으로 답변을 생성하고, 스스로 피드백을 통해 지속적으로 개선.
2. 다양한 도메인 적용 가능:
• 컴퓨터 과학, 생물의학, 신경과학, 물리학 등 다양한 과학 분야에 활용 가능.
3. 개방형 접근:
• 모든 코드, 데이터, 모델을 오픈 소스로 공개.
OpenScholar 과학 문헌 검색과 요약의 동작 원리

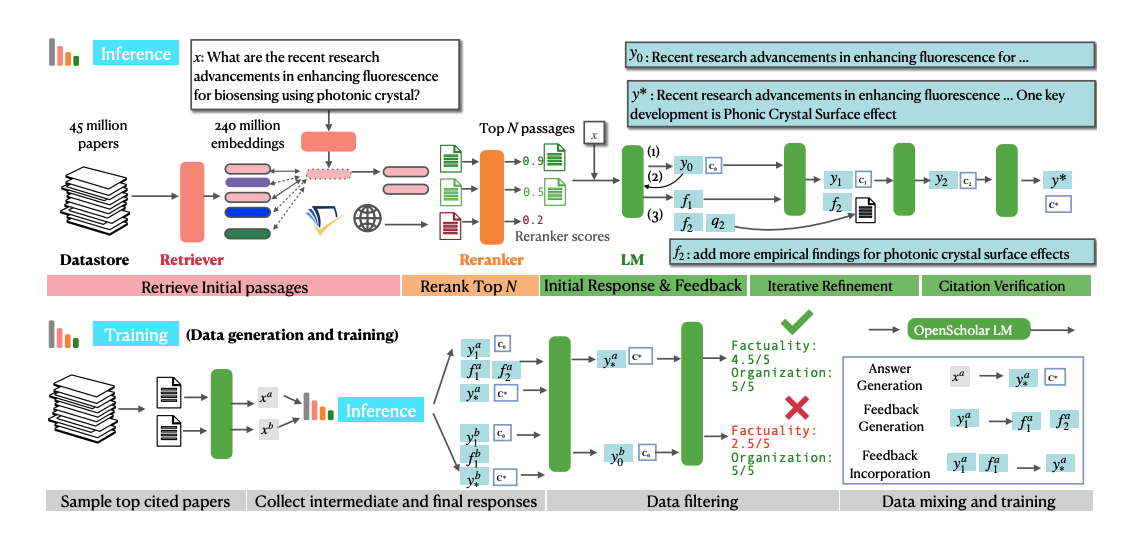
OpenScholar는 **검색 증강 언어 모델(Retrieval-Augmented Language Model, RAG)**로 설계되어, 과학적 질문에 대한 정확하고 신뢰할 수 있는 답변을 생성합니다. 이를 위해, OpenScholar는 데이터 검색, 재정렬, 답변 생성, 피드백 적용 등 여러 단계를 거칩니다. 아래는 OpenScholar의 동작 순서를 단계별로 소개합니다.
1. 입력 질문 처리
사용자가 OpenScholar에 질문을 입력하면, 모델은 해당 질문을 분석하고 관련 문헌을 찾기 위한 검색 쿼리를 생성합니다.
예: “광학 나노입자의 냉각 기술의 최신 연구는 무엇인가요?”
2. 데이터스토어에서 관련 문헌 검색
OpenScholar는 4,500만 개의 오픈 액세스 논문으로 구성된 **OpenScholar 데이터스토어(OSDS)**에서 관련 텍스트를 검색합니다.
• Bi-Encoder Retriever: 입력 질문을 밀집 표현(embedding)으로 변환하고, 데이터스토어에서 관련성 높은 문단을 찾아냅니다.
• 초기 검색 결과: 상위 100개 이상의 관련 문단이 선택됩니다.
3. 검색 결과 재정렬
검색된 문단은 Cross-Encoder Reranker에 의해 재정렬됩니다.
• Cross-Encoder는 질문과 각 문단을 동시에 분석하여, 질문과의 연관성을 더 정확히 평가합니다.
• 최종적으로 상위 N개의 문단(예: 상위 10개)이 선택됩니다.
4. 초기 응답 생성
언어 모델은 선택된 문단과 입력 질문을 기반으로 초기 답변을 생성합니다.
• 초기 답변(y₀): 질문에 대한 간단한 응답과 인용 정보를 포함합니다.
• 예: “현재 가장 널리 사용되는 냉각 방법은 피드백 냉각입니다.”
5. 자체 피드백(self-feedback) 생성
모델은 초기 답변을 검토하고, 추가적으로 개선해야 할 점을 피드백 형태로 생성합니다.
• 피드백 예시:
• “응답에 실험적 결과를 추가하세요.”
• “보다 다양한 방법론을 포함하세요.”
6. 피드백을 반영한 답변 개선
피드백을 기반으로 추가적인 문단을 검색하고, 응답을 반복적으로 개선합니다.
• 반복적 업데이트: 모델은 초기 응답(y₀)에 피드백(f₁, f₂…)을 반영하여 업데이트된 응답(y₁, y₂…)을 생성합니다.
• 이 과정은 사전 정의된 횟수 또는 피드백이 모두 해결될 때까지 반복됩니다.
7. 인용 검증 및 최종 응답 생성
최종 응답을 생성하기 전에, 모델은 모든 과학적 주장에 대한 인용이 적절한지 검증합니다.
• 검증 절차:
• 모든 주장에 적절한 출처가 있는지 확인.
• 출처가 신뢰할 수 있는 논문인지 점검.
• 최종 응답에는 정확한 인용 정보가 포함됩니다.
• 예: “피드백 냉각 기술은 광학적으로 트랩된 마이크로스피어를 밀리켈빈 수준까지 냉각할 수 있습니다"
8. 최종 응답 출력
개선된 답변과 인용 정보를 포함한 최종 결과를 사용자에게 제공합니다.
OpenScholar의 사용 목적
OpenScholar는 연구자와 과학자들이 효율적이고 정확한 문헌 검색과 문헌 요약을 통해 시간을 절약하고, 더 나은 연구 결과를 도출할 수 있도록 설계되었습니다. 주요 사용 목적은 다음과 같습니다:
• 문헌 검색: 특정 질문에 대한 관련 논문과 내용을 검색
• 문헌 요약: 여러 논문에서 중요한 내용을 추출해 하나의 응답으로 정리
• 인용 생성: 정확한 출처와 함께 신뢰할 수 있는 답변 제공
사용 방법
Demo: https://openscholar.allen.ai/
Ai2 OpenScholar
openscholar.allen.ai
OpenScholar는 다음과 같은 단계로 사용됩니다:
1. 질문 입력: 사용자는 특정 과학적 질문을 입력합니다.

2. 문헌 검색: OpenScholar는 4,500만 개 이상의 오픈 액세스 논문에서 관련 데이터를 검색합니다.
3. 답변 생성: 검색한 데이터를 바탕으로 질문에 대한 요약과 함께 정확한 인용 정보를 포함한 답변을 생성합니다.

자세히 알아보기
Paper: https://openscholar.allen.ai/paper
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries
arxiv.org
OpenScholar code: https://github.com/AkariAsai/OpenScholar
GitHub - AkariAsai/OpenScholar: This repository includes the official implementation of OpenScholar: Synthesizing Scientific Lit
This repository includes the official implementation of OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs. - GitHub - AkariAsai/OpenScholar: This repository includes the...
github.com
ScholarQABench code: https://github.com/AkariAsai/ScholarQABench
GitHub - AkariAsai/ScholarQABench: This repository contains ScholarQABench data and evaluation pipeline.
This repository contains ScholarQABench data and evaluation pipeline. - GitHub - AkariAsai/ScholarQABench: This repository contains ScholarQABench data and evaluation pipeline.
github.com
Expert evaluation code: https://github.com/AkariAsai/OpenScholar_ExpertEval
GitHub - AkariAsai/OpenScholar_ExpertEval: This repository contains expert evaluation interface and data evaluation script for t
This repository contains expert evaluation interface and data evaluation script for the OpenScholar project. - GitHub - AkariAsai/OpenScholar_ExpertEval: This repository contains expert evaluation...
github.com
Model checkpoints, index, data: https://huggingface.co/collections/OpenScholar/openscholar-v1-67376a89f6a80f448da411a6
OpenScholar_V1 - a OpenScholar Collection
The set of models, index, data associated with the paper "OpenScholar: Synthesizing Scientific Literature with Retrieval-Augmented LMs".
huggingface.co
'[AI] > 모델' 카테고리의 다른 글
| 한국어 자연어 처리 언어 모델 Exaone 소개 (0) | 2024.11.16 |
|---|