
HPE가 무엇인지 궁금해서 직접 공부해보고 지원하기로 했다!!
계획서 : https://eunmastudio.tistory.com/46
깃허브 : https://github.com/Oh-JunTaek/sideProject/tree/main/Human%20Pose%20Estimation
준비물
데이터 셋 선정 : COCO
- 대규모 데이터와 다양성:
COCO 데이터셋은 수십만 장의 이미지와 다양한 환경, 포즈, 인물 구성을 포함하고 있어, 실제 애플리케이션에서 발생할 수 있는 다양한 상황을 모델이 학습할 수 있도록 돕습니다. - 풍부한 어노테이션:
사람의 keypoints(관절) 어노테이션이 정밀하게 제공되며, 객체 검출, 세분화 등 다양한 태스크를 위한 어노테이션이 함께 포함되어 있어, 여러 연구 및 응용 분야에서 활용하기 좋습니다. - 표준 벤치마크:
COCO 데이터셋은 컴퓨터 비전 분야에서 널리 사용되는 표준 벤치마크로, 모델 성능 비교 및 평가에 있어 기준 역할을 합니다. 이를 통해 연구 결과를 다른 연구와 비교하거나, 기존 모델과의 성능 차이를 명확히 할 수 있습니다. - 활발한 커뮤니티 및 라이브러리 지원:
COCO 데이터셋은 pycocotools와 같은 라이브러리를 통해 쉽게 사용할 수 있으며, 관련 문서와 튜토리얼, 오픈 소스 프로젝트들이 많아 초기 학습 및 구현에 큰 도움이 됩니다.

그러나 데이터셋 다운로드가 쉽지는 않습니다... 검사 결과 http와 https사이의 보안 문제인 듯 합니다.
그래서 다운로드 링크를 직접 변경해서 설치를 시작! : https://images.cocodataset.org/zips/train2017.zip

마찬가지로 검증 데이터셋도 같은 방식으로 설치 : https://images.cocodataset.org/zips/val2017.zip
모델 아키텍처 설계 및 구현
- 입력/출력 정의:
- 입력: 전처리된 이미지 (예: 256×256 또는 368×368 등)
- 출력: 각 관절(키포인트)에 해당하는 heatmap (예: 17개의 heatmap, 각 heatmap은 해당 관절의 존재 확률을 나타냄)
- 구현 라이브러리:
- TensorFlow/Keras 또는 PyTorch 중 하나를 선택합니다.
- 선택한 라이브러리에 맞춰 모델 구조(예: 컨볼루션 레이어, 업샘플링 레이어 등)를 설계합니다.
- CNN 기반 Heatmap Regression 모델 (PyTorch)
import torch
import torch.nn as nn
import torch.nn.functional as F
# 모델 클래스 정의: SimplePoseNet
class SimplePoseNet(nn.Module):
def __init__(self, num_keypoints=17):
super(SimplePoseNet, self).__init__()
# Feature extractor: 입력 이미지에서 특징을 추출하는 부분입니다.
# 1) 첫 번째 Convolution: 채널 수 3 (RGB 이미지) -> 64, 커널 크기 7, stride 2, padding 3
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
# 2) 두 번째 Convolution: 64 -> 128, 커널 크기 3, stride 2, padding 1
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
# 3) 세 번째 Convolution: 128 -> 256, 커널 크기 3, stride 2, padding 1
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)
self.bn3 = nn.BatchNorm2d(256)
# 업샘플링(Deconvolution): 256 채널에서 num_keypoints (기본 17) 채널의 heatmap 생성
self.deconv = nn.ConvTranspose2d(256, num_keypoints, kernel_size=4, stride=2, padding=1)
def forward(self, x):
# 입력 x에 대해 각 층을 순서대로 통과시킵니다.
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
# 마지막에 deconvolution을 적용하여 heatmap 생성
heatmaps = self.deconv(x)
return heatmaps
# 모델 인스턴스 생성 및 출력
if __name__ == "__main__":
model = SimplePoseNet(num_keypoints=17)
print(model)전처리 함수 정의
- 이미지 파일을 열고 RGB로 변환한 후,
- 리사이즈하여 지정된 크기로 맞추고,
- 텐서로 변환한 뒤,
- 정규화를 통해 픽셀 값의 분포를 조정하여,
- 모델 학습에 바로 사용할 수 있는 PyTorch 텐서를 반환합니다.
- CNN 기반 Heatmap Regression 모델 (PyTorch)
from PIL import Image
import torchvision.transforms as transforms
def preprocess_image_pil(image_path, target_size=(256, 256)):
"""
이미지 경로를 받아 target_size 크기로 리사이즈하고, 텐서 변환 및 정규화를 수행합니다.
Args:
image_path (str): 이미지 파일의 경로.
target_size (tuple): (width, height) 형태의 원하는 출력 크기.
Returns:
torch.Tensor: 전처리된 이미지 텐서.
"""
# 전처리 파이프라인 정의 (여기서는 일반적인 ImageNet 정규화 값 사용)
transform = transforms.Compose([
transforms.Resize(target_size),
transforms.ToTensor(), # 0~1 사이의 값으로 변환 및 (C, H, W) 텐서 형식
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# PIL Image로 읽어오기
image = Image.open(image_path).convert("RGB")
image = transform(image)
return image
커스텀 데이터셋 클래스 (CustomImageDataset) 정의
- 목적:
지정된 폴더에서 이미지 파일들을 읽어오고, 전처리 함수를 적용하여 모델 학습에 사용할 수 있는 텐서를 반환합니다. - 세부 기능:
- __init__:
- 전달받은 image_dir 폴더 내에서 확장자가 .jpg인 모든 파일명을 목록으로 저장합니다.
- transform_func 인자를 통해, 이미지 전처리 함수(예: preprocess_image_pil)를 저장합니다.
- __len__:
- 데이터셋에 포함된 이미지 파일의 총 개수를 반환합니다.
- __getitem__:
- 주어진 인덱스에 해당하는 이미지 파일 경로를 구성하고, 전처리 함수를 통해 해당 이미지를 텐서로 변환한 후 반환합니다.
- (추후) 어노테이션 정보도 함께 반환하도록 확장할 수 있습니다.
- __init__:
from torch.utils.data import Dataset
import os
class CustomImageDataset(Dataset):
def __init__(self, image_dir, transform_func):
"""
Args:
image_dir (str): 이미지들이 저장된 폴더 경로.
transform_func (callable): 이미지를 전처리할 함수 (예: preprocess_image_pil).
"""
self.image_dir = image_dir
self.transform_func = transform_func
# 이미지 파일명 목록을 수집 (확장자가 jpg인 파일들만)
self.image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
image_path = os.path.join(self.image_dir, self.image_files[idx])
# 전처리 함수를 통해 이미지 텐서를 얻음
image_tensor = self.transform_func(image_path)
# (추후) 어노테이션 정보도 함께 반환하도록 수정 가능
return image_tensorDataLoader 구성
목적
CustomImageDataset 클래스를 통해 생성한 데이터셋을 배치 단위로 로드하여, 모델에 입력할 수 있도록 만드는 것입니다.
작업 내용:
- torch.utils.data.DataLoader를 이용해 데이터셋을 배치 단위로 읽어옵니다.
- 배치 단위로 불러온 데이터의 shape이나 내용이 올바른지 확인합니다.
from torch.utils.data import DataLoader
from dataset import CustomImageDataset
from preprocessing import preprocess_image_pil
def create_dataloader(image_dir, batch_size=4, shuffle=True, num_workers=0):
"""
지정된 이미지 폴더에서 데이터를 로드하는 DataLoader를 생성합니다.
Args:
image_dir (str): 이미지들이 저장된 폴더 경로.
batch_size (int): 배치 크기.
shuffle (bool): 데이터 셔플 여부.
num_workers (int): 데이터를 로드할 때 사용할 서브 프로세스의 수.
Returns:
DataLoader: 구성된 PyTorch DataLoader 객체.
"""
dataset = CustomImageDataset(
image_dir=image_dir,
transform_func=preprocess_image_pil
)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)
return dataloaderpycocotools를 이용한 키포인트 어노테이션 로드 흐름
- pycocotools 설치
COCO 어노테이션(.json)을 쉽게 파싱하기 위해 pycocotools 라이브러리를 사용합니다. - 어노테이션 파일 로드
- person_keypoints_train2017.json (훈련용)
- person_keypoints_val2017.json (검증용)
을 Python 코드에서 로드합니다.
- 데이터셋 클래스 구성
- 각 이미지에 대한 키포인트(관절) 좌표를 불러와서, 이를 "훈련에 사용할 정답(ground truth)" 형태로 가공합니다.
- 이미지는 기존처럼 preprocess_image_pil 등을 이용해 전처리합니다.
- (선택) Heatmap 생성 로직
- Human Pose Estimation에서는 각 관절 위치에 대한 Heatmap을 만들어 학습하는 방식을 자주 사용합니다.
- 만약 직접 CNN을 구성하여 Heatmap Regression 방식으로 학습하려면, 각 관절마다 2D 가우시안 분포 등을 그려서 지도(heatmap)를 만드는 로직이 필요합니다.
- DataLoader로 묶어서 모델 학습 단계로 연결
- 최종적으로 torch.utils.data.DataLoader에 데이터셋을 넣어 batch 단위로 로드하고, 모델에 입력하여 학습을 진행할 수 있습니다.
from pycocotools.coco import COCO
import os
# 예: COCO 2017 train 어노테이션 JSON 파일
train_annotation_file = r"C:\Users\dev\Documents\GitHub\sideProject\Human Pose Estimation\data\annotations\person_keypoints_train2017.json"
coco_train = COCO(train_annotation_file)
# 이미지 ID 목록 가져오기
img_ids = coco_train.getImgIds()
# 첫 번째 이미지 정보 로드
img_info = coco_train.loadImgs(img_ids[0])[0]
print("이미지 파일명:", img_info['file_name'])
print("이미지 ID:", img_info['id'])
# 해당 이미지의 어노테이션(= 사람 키포인트 정보 등) 로드
ann_ids = coco_train.getAnnIds(imgIds=img_info['id'], iscrowd=False)
anns = coco_train.loadAnns(ann_ids)
print("키포인트 정보 예시:", anns)“이미지 + 키포인트”를 합쳐서 모델 학습에 사용하기
여기까지는 이미지 자체를 로딩하고 전처리하는 과정과, 키포인트 JSON으로부터 원하는 정보를 얻는 과정을 별도로 해봤습니다. 실제 Human Pose Estimation 모델을 학습하려면, 둘을 하나의 Dataset 안에서 결합**해줘야 합니다.
- COCO Pose Dataset 작성 (이미지 + 키포인트)
- 새로운 Dataset 클래스를 만들어, COCO 객체(pycocotools.coco.COCO)와 이미지를 함께 로딩합니다.
- 한 이미지에 여러 사람(키포인트)이 있을 수 있으므로, 단순히 첫 번째 사람만 사용하거나, 멀티 퍼슨 처리를 지원하도록 구현할 수 있습니다.
- Heatmap 생성을 원한다면, 키포인트 좌표를 Heatmap 형태로 변환하는 로직을 넣습니다. (가우시안 블러, 원 그리기 등)
import os
from torch.utils.data import Dataset
from pycocotools.coco import COCO
from PIL import Image
import torchvision.transforms as transforms
import torch
import numpy as np
import cv2 # Heatmap 그릴 때 유용
class COCOPoseDataset(Dataset):
def __init__(self, img_dir, ann_file, input_size=(256, 256)):
self.img_dir = img_dir
self.coco = COCO(ann_file)
self.img_ids = self.coco.getImgIds()
self.input_size = input_size
# 예시 전처리 파이프라인
self.transform = transforms.Compose([
transforms.Resize(self.input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.img_ids)
def __getitem__(self, idx):
img_id = self.img_ids[idx]
img_info = self.coco.loadImgs(img_id)[0]
image_path = os.path.join(self.img_dir, img_info['file_name'])
# 이미지 로드
image = Image.open(image_path).convert('RGB')
# 키포인트 로드
ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=False)
anns = self.coco.loadAnns(ann_ids)
# (간단 예시) 첫 번째 사람만 키포인트 사용
if len(anns) > 0 and 'keypoints' in anns[0]:
keypoints = anns[0]['keypoints']
else:
# 사람이 없거나 키포인트가 없는 경우
keypoints = [0]*(17*3) # 17개 관절 * (x,y,v)
# Heatmap 생성(옵션): 모델이 Heatmap Regression 방식을 쓸 경우
# 간단히 64x64 크기로 줄여서 관절 위치 찍기 예시
heatmap_size = (self.input_size[1]//4, self.input_size[0]//4)
num_keypoints = 17
heatmaps = np.zeros((num_keypoints, heatmap_size[0], heatmap_size[1]), dtype=np.float32)
# 가우시안 대신 원(circle)으로 표시 (예시)
for kp in range(num_keypoints):
x = keypoints[kp*3+0]
y = keypoints[kp*3+1]
v = keypoints[kp*3+2]
if v > 0: # 보이는 관절에만
# Heatmap 좌표로 스케일
x_hm = int(x * heatmap_size[1]/img_info['width'])
y_hm = int(y * heatmap_size[0]/img_info['height'])
if 0 <= x_hm < heatmap_size[1] and 0 <= y_hm < heatmap_size[0]:
cv2.circle(heatmaps[kp], (x_hm, y_hm), 2, 1.0, -1)
# 이미지 전처리
image_tensor = self.transform(image)
heatmaps_tensor = torch.from_numpy(heatmaps)
return image_tensor, heatmaps_tensor다음 단계
간단한 학습 루프 작성
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from coco_pose_dataset import COCOPoseDataset
from simple_pose_net import SimplePoseNet
def train_pose_model():
# 1) 하드웨어 디바이스 설정 (GPU 사용 가능시 cuda)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
# 2) Dataset & DataLoader 구성
img_dir = r"C:\Users\dev\Documents\GitHub\sideProject\Human Pose Estimation\data\train2017"
ann_file = r"C:\Users\dev\Documents\GitHub\sideProject\Human Pose Estimation\data\annotations\person_keypoints_train2017.json"
train_dataset = COCOPoseDataset(img_dir, ann_file)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# 3) 모델 준비
model = SimplePoseNet(num_keypoints=17).to(device)
# 4) 손실 함수 & 옵티마이저 설정
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 5) 학습 파라미터 설정
num_epochs = 5
# 6) 학습 루프
for epoch in range(num_epochs):
model.train() # 학습 모드
running_loss = 0.0
for batch_idx, (images, heatmaps) in enumerate(train_loader):
# 배치를 디바이스로 이동 (GPU 사용 시)
images = images.to(device)
heatmaps = heatmaps.to(device)
# forward
outputs = model(images)
loss = criterion(outputs, heatmaps)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 로그 기록
running_loss += loss.item()
if (batch_idx + 1) % 50 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{batch_idx+1}/{len(train_loader)}], "
f"Loss: {loss.item():.4f}")
# 에포크별 평균 Loss 출력
epoch_loss = running_loss / len(train_loader)
print(f"==> Epoch [{epoch+1}/{num_epochs}] Mean Loss: {epoch_loss:.4f}")
print("Training finished.")
if __name__ == "__main__":
train_pose_model()
- 디바이스 설정
- GPU가 사용 가능하면 GPU를 사용하고, 아니면 CPU로 사용합니다.
-
python복사편집device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device)
- Dataset & DataLoader
- 이전에 만들었던 COCOPoseDataset을 사용하여, 한 번에 (이미지, heatmaps) 배치를 가져옵니다.
- 손실 함수 & 옵티마이저
- MSELoss: 모델의 예측 Heatmap과 정답 Heatmap 간의 Mean Squared Error를 계산.
- Adam: 비교적 안정적으로 학습 가능한 옵티마이저.
- 학습 루프 구조
- 에포크(num_epochs)만큼 반복하면서, 각 배치(batch_idx)마다 다음을 수행:
- forward pass: outputs = model(images)
- loss 계산: loss = criterion(outputs, heatmaps)
- 역전파(gradient backprop): loss.backward()
- 옵티마이저 업데이트: optimizer.step()
- running_loss에 배치별 loss를 누적하여, 에포크가 끝난 후 평균 Loss를 출력합니다.
- 에포크(num_epochs)만큼 반복하면서, 각 배치(batch_idx)마다 다음을 수행:
- 로그 / 모니터링
- (batch_idx + 1)이 50 배수일 때마다 중간 Loss를 출력하도록 예시 설정
- 에포크가 끝나면 해당 에포크의 평균 Loss(epoch_loss)를 표시
cuda를 인식하지 못해서!!!

cuda설치를 하고 왔습니다.

성공적으로 그래픽카드를 괴롭히기 시작했습니다.
모델을 사용해 새로운 이미지에서 키포인트 예측
학습된 모델을 사용해서 새로운 이미지를 입력하고 키포인트를 예측하는 Inference 코드를 작성합니다.
import torch
import numpy as np
import cv2
from PIL import Image
import torchvision.transforms as transforms
from simple_pose_net import SimplePoseNet
# 디바이스 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 저장된 모델 불러오기
model = SimplePoseNet(num_keypoints=17).to(device)
model.load_state_dict(torch.load("pose_model.pth", map_location=device))
model.eval() # 모델을 평가 모드로 설정
# 이미지 전처리 함수
def preprocess_image(image_path, target_size=(256, 256)):
transform = transforms.Compose([
transforms.Resize(target_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = Image.open(image_path).convert("RGB")
image = transform(image).unsqueeze(0).to(device) # 배치 차원 추가 후 GPU로 이동
return image
# 예측 수행
def predict_pose(image_path):
image = preprocess_image(image_path)
with torch.no_grad(): # 그래디언트 계산 비활성화
output = model(image) # 모델 실행 (출력은 (1, 17, 64, 64) 형태의 Heatmap)
return output.cpu().numpy()
# 테스트 이미지에 대해 실행
image_path = "path/to/your/image.jpg" # 예측할 실제 이미지 경로 입력
heatmaps = predict_pose(image_path)
print("✅ Inference completed! Heatmap shape:", heatmaps.shape)

예측 결과 시각화
학습된 모델이 예측한 키포인트를 실제 이미지 위에 시각적으로 표현하면 직관적으로 결과를 볼 수 있습니다.
import cv2
import numpy as np
import torch
from inference import predict_pose, preprocess_image
from PIL import Image
# 키포인트를 원본 이미지 위에 그리는 함수
def draw_keypoints(image_path, heatmaps):
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # OpenCV는 BGR, PIL은 RGB이므로 변환
num_keypoints = heatmaps.shape[1]
heatmap_size = heatmaps.shape[2]
# 이미지 크기에 맞게 키포인트 좌표 변환
height, width, _ = image.shape
scale_x = width / heatmap_size
scale_y = height / heatmap_size
for kp in range(num_keypoints):
heatmap = heatmaps[0, kp, :, :]
y, x = np.unravel_index(np.argmax(heatmap), heatmap.shape)
x = int(x * scale_x)
y = int(y * scale_y)
# 키포인트를 원본 이미지 위에 그리기
cv2.circle(image, (x, y), 5, (0, 255, 0), -1)
return image
# 테스트 이미지에 대해 실행
image_path = "path/to/your/image.jpg" # 실제 이미지 경로
heatmaps = predict_pose(image_path)
result_image = draw_keypoints(image_path, heatmaps)
# 결과 저장 및 출력
cv2.imwrite("result.jpg", cv2.cvtColor(result_image, cv2.COLOR_RGB2BGR))
cv2.imshow("Pose Estimation", result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()✅ Inference completed! Heatmap shape: (1, 17, 64, 64)
키포인트 0: (0, 0)
키포인트 1: (0, 0)
키포인트 2: (0, 0)
키포인트 3: (0, 0)
키포인트 4: (0, 0)
키포인트 5: (0, 0)
키포인트 6: (0, 0)
키포인트 7: (0, 0)
키포인트 8: (0, 0)
키포인트 9: (0, 0)
키포인트 10: (0, 0)
키포인트 11: (0, 0)
키포인트 12: (0, 0)
키포인트 13: (0, 0)
키포인트 14: (0, 0)
키포인트 15: (0, 0)
키포인트 16: (0, 0)문제가 발생했습니다! 키포인트를 제대로 찾지 못하는 것 같아서 확인이 필요합니다.
원인을 예상해보고 하나씩 접근해 보겠습니다.
1. 모델 예측값이 전부 0
np.max(heatmaps) 출력하여 Heatmap 값 확인

🔹 현재 모델이 예측한 Heatmap 값이 너무 작아서, 키포인트를 찾기 어려움
🔹 Heatmap을 보정하여, 키포인트를 더 뚜렷하게 찾도록 개선해야 함현재 np.argmax(heatmap)을 사용할 때, 값이 작아서 강한 신호를 찾기 어려움
👉 Heatmap을 0~1 범위로 정규화하면, 상대적인 강한 키포인트를 찾을 수 있음!
🔹 Heatmap을 정규화하여 강한 신호 감지
for kp in range(num_keypoints):
heatmap = heatmaps[0, kp, :, :]
# 🔹 Heatmap을 정규화하여 최대값이 1이 되도록 조정
heatmap = (heatmap - np.min(heatmap)) / (np.max(heatmap) - np.min(heatmap) + 1e-9)
# 🔹 정규화된 Heatmap에서 가장 강한 신호 위치 찾기
y, x = np.unravel_index(np.argmax(heatmap), heatmap.shape)
x = int(x * scale_x)
y = int(y * scale_y)
해결하지 못했다...
하지만 잘못된 샘플을 가져왔을 수 있다는 생각에 키포인트가 많은 사진을 찾아보기로 했습니다.
from pycocotools.coco import COCO
# 어노테이션 파일 로드 (훈련 or 검증 데이터셋 선택)
ann_file =
coco = COCO(ann_file)
# 모든 이미지 ID 가져오기
img_ids = coco.getImgIds()
# 키포인트 개수 기준으로 정렬
img_keypoints = []
for img_id in img_ids:
ann_ids = coco.getAnnIds(imgIds=img_id, iscrowd=False)
anns = coco.loadAnns(ann_ids)
# 현재 이미지의 모든 사람에 대해 키포인트 개수 합산
total_keypoints = sum([ann["num_keypoints"] for ann in anns if "num_keypoints" in ann])
img_keypoints.append((img_id, total_keypoints))
# 키포인트가 많은 상위 5개 이미지 출력
img_keypoints = sorted(img_keypoints, key=lambda x: x[1], reverse=True)[:5]
print("키포인트 많은 상위 5개 이미지:", img_keypoints)


하지만 여전히 잘 찾아내지 못하고 있습니다.
학습상태를 의심해보았습니다.
import torch
from simple_pose_net import SimplePoseNet
# 디바이스 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 모델 로드
model = SimplePoseNet(num_keypoints=17).to(device)
try:
model.load_state_dict(torch.load("pose_model.pth", map_location=device))
print("✅ 모델이 성공적으로 로드되었습니다.")
except Exception as e:
print("❌ 모델 로드 실패:", e)
# 가중치 확인 (일부 레이어 값 출력)
for name, param in model.named_parameters():
print(f"{name}: {param.mean().item():.6f}")
break # 너무 길어지지 않도록 첫 번째 레이어만 출력
아무래도 학습반복을 2회만 해서 그런 것 같습니다.

바로 횟수의 문제가 아님을 알 수 있었습니다.
현재 문제 분석
🔹 Loss가 0.0010에서 줄어들지 않는 이유?
1️⃣ 모델이 너무 단순해서 복잡한 Pose Estimation을 학습하지 못할 가능성
→ 현재 SimplePoseNet이 너무 간단해서, 더 깊은 네트워크가 필요할 수도 있음
2️⃣ 학습률(Learning Rate)이 너무 커서 학습이 수렴하지 않음
→ lr=1e-3은 Pose Estimation에서는 너무 클 수도 있음
→ 1e-4로 줄이면 학습이 더 안정적으로 진행될 가능성
3️⃣ 손실 함수(MSELoss)가 적절하지 않을 가능성
→ MSELoss 대신 Smooth L1 Loss(HuberLoss) 또는 KLDivLoss 시도 가능
4️⃣ 데이터 전처리(Preprocessing) 문제
→ Heatmap이 너무 작은 크기(64x64)로 축소되면서 정보가 손실되었을 가능성
조금 더 복잡한 모델을 구성해 보겠습니다.
import torchvision.models as models
class ResNetPoseNet(nn.Module):
def __init__(self, num_keypoints=17):
super(ResNetPoseNet, self).__init__()
self.backbone = models.resnet18(pretrained=True) # ResNet18 사용
self.backbone.fc = nn.Linear(512, num_keypoints * 2) # 17개 관절 * (x, y)
def forward(self, x):
x = self.backbone(x)
return x.view(-1, 17, 2) # (batch, num_keypoints, 2)비교 분석
모델레이어 개수파라미터 수(approx)특징
| SimplePoseNet | 4개 (Conv + BN + Deconv) | 약 1~2M | 단순한 CNN 구조, 작은 데이터셋에서 학습 가능 |
| ResNetPoseNet (ResNet18 기반) | 18개 이상 (ResNet18) | 약 11M | 강력한 Feature Extractor, 복잡한 데이터 학습 가능 |
ResNet 기반 모델이 얼마나 복잡해졌는가?
1. SimplePoseNet 은 작은 CNN 네트워크로, 4개의 주요 레이어(Conv + BN + Deconv)만 존재
2. ResNetPoseNet 은 18개 이상의 레이어(ResNet18 구조) 를 포함, 11M 이상의 파라미터를 가짐
3. ResNet은 Skip Connection을 포함 → Gradient 소실 방지 & 더 깊은 특징 학습 가능
4.기존 모델은 Heatmap을 예측했지만, ResNetPoseNet은 직접 (x, y) 좌표를 예측
ResNetPoseNet 적용 후 기대 효과
모델학습 속도정확도(예상)특징
| SimplePoseNet | 빠름 (간단한 네트워크) | 낮음 | 연산량이 작아 빠르지만 복잡한 포즈를 잘 못 찾을 가능성 |
| ResNetPoseNet | 느림 (복잡한 네트워크) | 높음 | ResNet 기반 강력한 특징 추출로 포즈를 정확하게 예측 가능 |
1. ResNetPoseNet을 사용하면 더 정교한 포즈 인식 가능!
2. 다만 학습 속도는 다소 느려질 수 있음 (하지만 정확도 향상을 위해 충분한 Trade-off)

범위를 0~1로 설정하지 않아서 수치가 커졌지만 계속 로스값이 줄어들고 있음을 확인

추론을 완료했고 이제 결과를 시각화 해봅시다.
import cv2
import numpy as np
import torch
from PIL import Image
import matplotlib.pyplot as plt
# 추론 결과 로드
predicted_keypoints = np.array([
[396.91986, 125.40627], [384.28397, 113.19349], [357.68848, 108.36974],
[378.0459, 100.082695], [147.31769, 72.80783], [439.58835, 154.01808],
[393.80966, 156.50447], [448.84732, 205.02428], [374.3959, 203.47243],
[439.41943, 224.10767], [366.96207, 216.2085], [441.38068, 272.10345],
[408.06808, 271.70392], [398.31348, 299.77182], [371.58908, 297.96512],
[379.52823, 351.85037], [355.95764, 350.56714]
])
# 원본 이미지 로드
image_path = "경로"
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # OpenCV는 BGR이므로 RGB로 변환
# 키포인트 그리기
for (x, y) in predicted_keypoints:
cv2.circle(image, (int(x), int(y)), 5, (255, 0, 0), -1) # 🔵 파란색 점
# 결과 이미지 출력
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.axis("off")
plt.title("Pose Estimation Keypoints")
plt.show()

정확도 이슈는 있지만 어느정도 적중률을 보인다는 것은 방향성을 잘 잡고 있다는 뜻으로 해석이 된다!!
📌 추가 고도화 계획
✅ 1. 224x224 이미지 전처리 최적화
- ResNet 모델은 기본적으로 (224, 224) 크기의 입력을 받도록 설계됨
- 따라서 전처리에서 이미지 크기를 (256, 256) → (224, 224) 로 변경
- 수정 코드 (coco_pose_dataset.py)
# coco_pose_dataset.py
self.input_size = (224, 224) # 기존 (256, 256) → (224, 224)
transforms.Resize(self.input_size)✅ 2. 키포인트 정규화
- 원본 픽셀 좌표를 (0~1) 범위로 정규화하면 학습이 더 안정적
- 수정 코드 (coco_pose_dataset.py)
# coco_pose_dataset.py
keypoints[:, 0] /= img_info["width"] # x 좌표 정규화
keypoints[:, 1] /= img_info["height"] # y 좌표 정규화✅ 3. 손실 함수 변경 (MSELoss → Smooth L1 Loss 사용)
- MSELoss는 작은 차이에 민감해서 노이즈가 클 경우 SmoothL1Loss가 더 효과적
- 수정 코드 (train.py)
# train.py
criterion = nn.SmoothL1Loss() # 기존 MSELoss() → SmoothL1Loss()✅ 4. 학습 횟수 증가 (Epoch 7 → 15)
- Loss가 계속 줄어드는 중이므로 추가 학습 진행
- 수정 코드 (train.py)
# train.py
num_epochs = 15 # 기존 7 → 15✅ 5. 키포인트 연결선 추가 (시각화 개선)
- 키포인트 점만 표시하는 것이 아니라 관절을 선으로 연결
- 수정 코드 (visualize.py)
# visualize.py
# 키포인트 그리기
for (x, y) in predicted_keypoints:
cv2.circle(image, (int(x), int(y)), 5, (255, 0, 0), -1) # 🔵 파란색 점
# 관절 연결선 추가
for (i, j) in COCO_SKELETON:
pt1 = tuple(predicted_keypoints[i].astype(int))
pt2 = tuple(predicted_keypoints[j].astype(int))
cv2.line(image, pt1, pt2, (0, 255, 0), 2) # 🟢 초록색 선으로 연결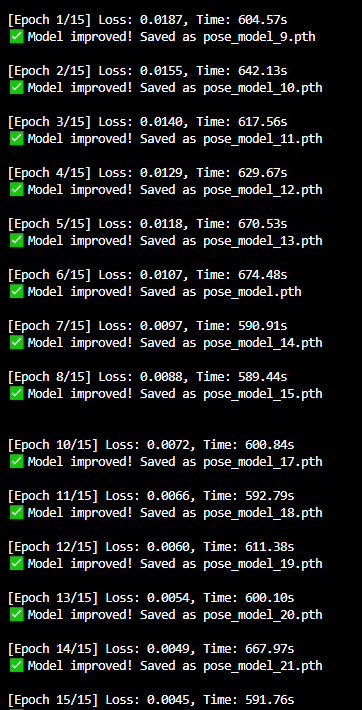
# COCO Keypoint 연결 정보
COCO_SKELETON = [
(0, 1), (0, 2), (1, 3), (2, 4), # 얼굴 (코-눈, 눈-귀 연결)
(5, 6), (5, 7), (6, 8), (7, 9), (8, 10), # 상체 (어깨-팔꿈치-손목 연결)
(5, 11), (6, 12), (11, 12), # 몸통 (어깨-골반 연결)
(11, 13), (12, 14), (13, 15), (14, 16) # 다리 (골반-무릎-발목 연결)
]
결과






얼굴쪽은 정확히 잡아내지 못하고(그래도 일정한 규칙? 으로 튀는 것을 확인)
그 외에는 어느정도 형태를 잘 잡아내는 것 같습니다.
로스율이 꾸준히 줄어드는데 15회 설정한 결과물인걸 감안하면
약 30회 정도 추가 학습을 시킨다면 정확도가 상당히 올라갈 것으로 고려됩니다!
그리고 얼굴쪽은 아무래도 coco데이터셋의 한계인 것으로 추정되기에 실습을 마치도록 하겠습니다!
'[STUDY] > [Single_Project]' 카테고리의 다른 글
| [CNN] 필기체 숫자 분류 딥러닝 모델 (0) | 2024.10.14 |
|---|