논문 : https://www.microsoft.com/en-us/research/uploads/prod/2024/11/Magentic-One.pdf
멀티 에이전트 Magentic-ONE
1. 소개
Magentic-One은 Microsoft Research에서 개발된 복잡한 문제 해결을 위한 다중 에이전트 시스템입니다. 이 연구는 Magentic-One의 일반주의적 접근과 다양한 도메인에서의 적용 가능성을 강조합니다. 본 리뷰에서는 논문의 주요 내용과 성능 평가, 한계와 위험 완화 전략 등을 분석하고, Magentic-One의 발전 가능성을 살펴보겠습니다.

- Magnetic-One:
- Magnetic-One은 범용 멀티 에이전트 팀으로, 오픈 소스로 구현되어 있습니다. 이 팀은 Coder, Computer Terminal, File Surfer, Web Surfer, Orchestrator의 다섯 가지 에이전트로 구성됩니다.
- 각 에이전트는 상태를 유지하는 웹 및 파일 브라우저, 커맨드 라인, Python 코드 실행기와 같은 도구를 사용할 수 있습니다.
- Orchestrator 에이전트는 고차원 목표를 달성하기 위해 여러 기능을 수행합니다. 작업 계획을 수립하고, 작업 진행 상황을 기록하며, 다른 에이전트에 작업을 지시하고, 작업이 멈추면 재시작 및 초기화하며, 작업이 완료되었는지 판단하는 역할을 합니다.
- AutoGenBench:
- AutoGenBench는 에이전트 벤치마크 평가를 위한 독립형 도구로, 오픈 소스로 제공됩니다.
- 이 도구는 에이전트 시스템의 성능을 구성, 실행, 보고하는 역할을 하며, 모든 실험이 동일한 초기 조건에서 시작되도록 보장하고, 에이전트들이 각 실험 간에 서로 간섭하지 않도록 합니다.
- 실험 결과 및 분석:
- Magnetic-One의 성능이 GAIA, WebArena, AssistantBench 벤치마크에서 높은 작업 완료율을 보이며, 다른 최첨단(SOTA) 시스템과 통계적으로 경쟁력 있는 결과를 보여줍니다.
- 실험에서는 각 에이전트의 기여도와 기능을 분석하며, 에러 분석을 통해 멀티 에이전트 접근 방식의 강점과 약점, 개선 가능성을 파악합니다.
2. 관련 연구
Magentic-One의 다중 에이전트 접근법은 기존의 단일 에이전트 시스템의 한계를 극복하고자 하는 시도입니다. 최근 연구들은 LLM(대규모 언어 모델)을 활용한 다양한 에이전트 시스템을 제안하고 있으며, 이러한 시스템들은 작업을 분해하고 다른 에이전트에게 할당하여 문제를 해결하는 방식으로 발전하고 있습니다. Magentic-One은 이러한 연구의 흐름을 반영하여, 여러 에이전트가 협력하여 복잡한 문제를 해결하도록 설계되었습니다.
3. 문제 설정
Magentic-One은 사람들이 직면하는 다양한 복잡한 작업을 해결하기 위해 설계되었습니다. 웹 탐색, 파일 조작, 코드 작성 등 여러 도메인에 걸친 문제를 해결하기 위해 다단계 추론과 계획 수립, 오류 복구 등의 기능이 요구됩니다. 이 시스템의 목표는 사람들이 직면하는 다양한 문제를 자동으로 해결함으로써 인간의 생산성을 증대시키는 것입니다.
Magnetic-One의 Orchestrator 에이전트가 작업을 관리하는 두 가지 루프, 즉 외부 루프와 내부 루프를 설명합니다. 각 루프는 작업을 추적하고, 에이전트에게 할당하며, 작업 완료를 위한 진행 상황을 관리하는 역할을 합니다.
구성 요소 및 과정:
- Task Ledger (작업 원장):
- 외부 루프에서 관리하며, 작업에 필요한 정보들을 기록합니다.
- 주어진 사실이나 확인된 사실, 찾아야 할 정보, 계산 또는 논리를 통해 유도해야 할 사실, 추측, 작업 계획 등이 포함됩니다.
- Orchestrator는 이 Task Ledger를 통해 작업의 초기 정보를 수집하고, 필요한 사항을 정리하여 계획을 세웁니다.
- Progress Ledger (진행 원장):
- 내부 루프에서 관리하며, 작업 진행 상황을 추적합니다.
- 작업이 완료되었는지, 비생산적인 루프가 발생하고 있는지, 진행이 있는지, 다음 지시사항이 무엇인지 등을 기록합니다.
- Orchestrator는 Progress Ledger를 지속적으로 업데이트하여 작업의 각 단계가 올바르게 진행되고 있는지 확인합니다.
- 루프 구조:
- 외부 루프: 배경이 연한 부분에 표시된 실선 화살표로, Task Ledger의 사실, 계획, 추측 등을 관리합니다. Orchestrator는 Task Ledger를 업데이트하고 작업이 잘 진행될 수 있도록 준비합니다.
- 내부 루프: 배경이 진한 부분에 점선 화살표로, Progress Ledger를 관리하며 작업의 진행 상황을 확인합니다. 작업이 완료되었는지 확인하고, 작업 진행이 없는 경우 일정 횟수만큼 대기하다가 작업을 재시작하거나 리셋합니다.
- Stall Detection: 만약 작업이 멈춘 경우(Progress being made? 가 No일 때), 중단 횟수를 확인하여 2회 이상 멈춘 경우 작업을 재설정합니다.
- 에이전트의 역할:
- Orchestrator는 각 에이전트에게 특정 작업을 할당하며, 각 에이전트는 할당된 작업에 따라 행동합니다.
- Coder: 코드를 작성하고 논리를 통해 작업을 해결합니다.
- Computer Terminal: Coder가 작성한 코드를 실행합니다.
- WebSurfer: 인터넷을 검색하거나 양식을 작성하는 등의 웹 탐색 작업을 수행합니다.
- FileSurfer: PDF, PPTX, WAV 파일 등 다양한 형식의 파일을 탐색합니다.
- 최종 결과 보고:
- 모든 작업이 완료되면 최종 답변 또는 추정된 답변을 보고하며, 작업의 전체 과정과 관찰된 내용의 기록을 함께 반환합니다.
이 시스템은 에이전트가 상호작용하는 부분적으로 관찰 가능한 마르코프 결정 프로세스(POMDP)로 묘사할 수 있습니다.
4. Magentic-One 개요
Magentic-One의 다중 에이전트 워크플로우
Magentic-One은 오케스트레이터(Orchestrator)라는 리드 에이전트를 중심으로 다중 에이전트가 협력하여 문제를 해결합니다. 오케스트레이터는 작업을 분해하고 각 에이전트에게 할당하며, 전체적인 진행 상황을 모니터링하고 필요 시 계획을 수정합니다. 이러한 워크플로우는 복잡한 문제를 단계별로 해결하는 데 효과적입니다.
Magentic-One의 에이전트들
- 오케스트레이터: 전체 계획을 수립하고 다른 에이전트들에게 작업을 분배하는 리더 역할을 합니다.
- 웹서퍼(WebSurfer): 웹 페이지 탐색 및 정보를 수집하는 역할을 합니다.
- 파일서퍼(FileSurfer): 로컬 파일 시스템에서 파일을 읽고 정보를 추출합니다.
- 코더(Coder): 다른 에이전트들이 수집한 정보를 바탕으로 코드를 작성하거나 분석하는 역할을 합니다.
- 컴퓨터터미널(ComputerTerminal): 작성된 코드를 실행하고 필요한 환경을 설정합니다.
5. 실험
AutoGenBench 및 설정
- Magentic-One의 성능은 AutoGenBench라는 벤치마크를 통해 평가되었습니다. AutoGenBench는 다중 에이전트 시스템의 성능을 평가하기 위한 도구로, 다양한 복잡한 시나리오에서의 작업 완료 능력을 테스트합니다. 실험은 여러 가지 설정에서 진행되었으며, 각 에이전트의 기능이 어떻게 협력하여 전체 성능을 향상시키는지 분석되었습니다.
결과
- Magentic-One은 GAIA, AssistantBench, WebArena와 같은 벤치마크에서 최첨단 기술과 유사한 성능을 보였습니다. 특히, 다중 에이전트가 협력하여 복잡한 문제를 해결하는 데 있어 높은 성공률을 기록했습니다. 실험 결과는 Magentic-One의 아키텍처가 다양한 작업에서 효율적이라는 것을 보여주며, 특히 계획 수립과 오류 복구 능력에서 강점을 나타냈습니다.
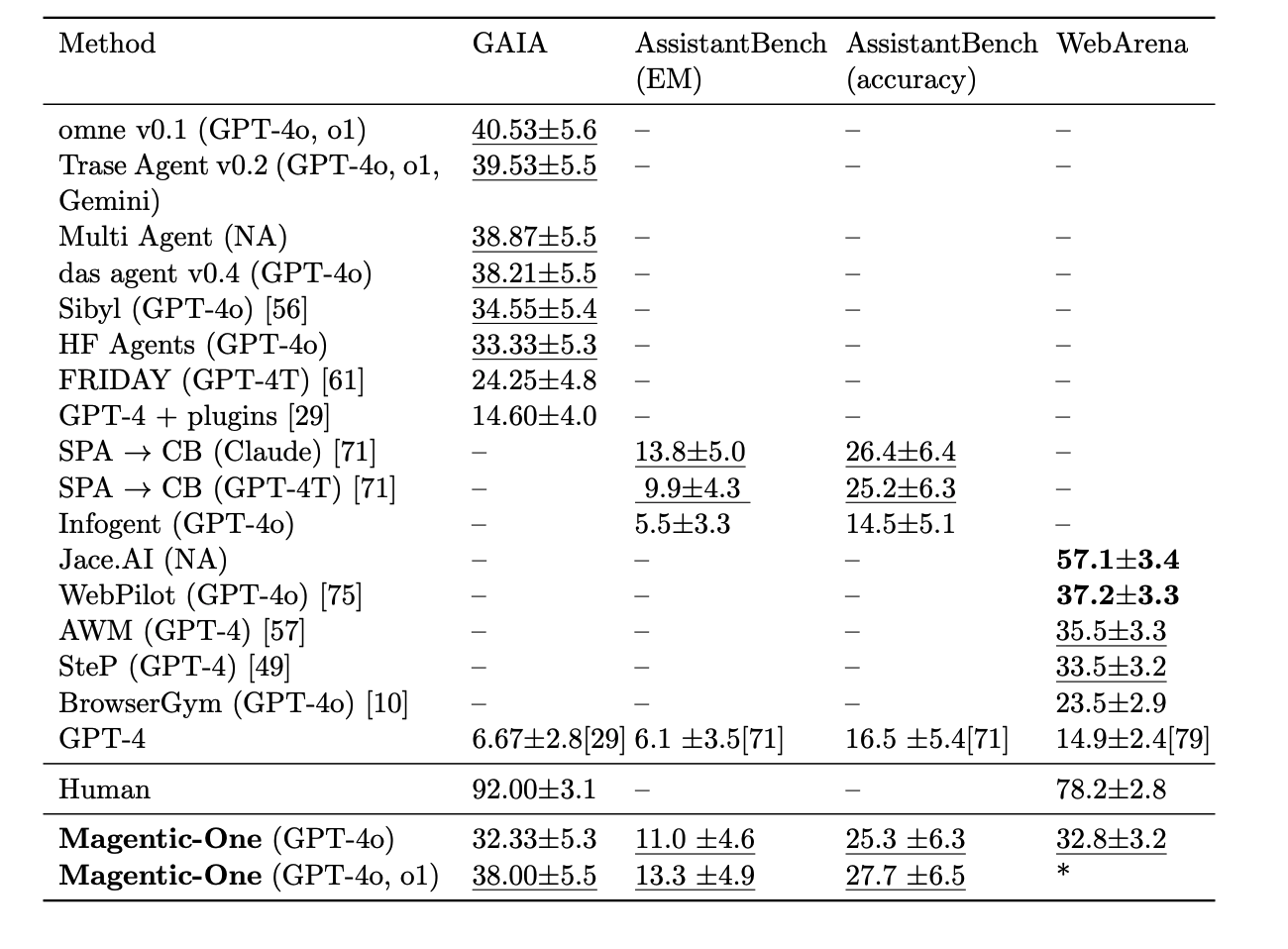
- Method (메서드): 각 시스템 또는 에이전트 방식이 표시된 열로, 다양한 시스템이 여러 모델(GPT-4, Claude 등)을 사용한 에이전트 방식을 나타냅니다. Magnetic-One을 포함해 여러 시스템이 비교됩니다.
- GAIA:
- GAIA 벤치마크에서는 Omne v0.1과 Trase Agent v0.2가 상대적으로 높은 점수를 기록했습니다.
- Magnetic-One의 성능은 두 가지 설정(GPT-4o, GPT-4o 및 o1)에서 각각 32.33±5.3과 38.00±5.5로 평가되었으며, 최상위 시스템보다는 낮지만 여러 다른 시스템보다 좋은 성능을 보입니다.
- AssistantBench (EM)와 AssistantBench (accuracy):
- AssistantBench에서는 특정 메서드들만 점수가 기록되어 있습니다.
- Magnetic-One은 EM 지표에서 11.0±4.6, accuracy 지표에서 25.3±6.3을 기록하였으며, 두 메서드에서 비교적 높은 성능을 보입니다.
- WebArena:
- WebArena 벤치마크에서는 Omne v0.1과 Human이 가장 높은 점수를 기록했습니다.
- Magnetic-One의 GPT-4o 설정이 32.8±3.2의 성능을 보였고, GPT-4o 및 o1 설정은 성능이 표시되지 않았습니다.
- Human 성능:
- 표에서 Human의 성능이 포함되어 있는데, 이는 사람이 해당 벤치마크에서 달성한 평균 성과입니다. 인간의 성능은 GAIA와 WebArena에서 매우 높은 점수(92.00±3.1, 78.2±2.8)를 기록하고 있으며, 이는 모델이 인간의 성능에 근접하기 위해 필요한 성과 기준을 제공합니다.
에이전트 성능 분석
- Magentic-One의 성능 분석 결과, 오케스트레이터의 효과적인 계획 수립과 각 에이전트의 협력이 시스템 성능에 중요한 역할을 한다는 것이 밝혀졌습니다. 오케스트레이터가 효율적으로 작업을 분해하고 에이전트 간 협력을 조율함으로써 복잡한 작업도 성공적으로 처리할 수 있었습니다.
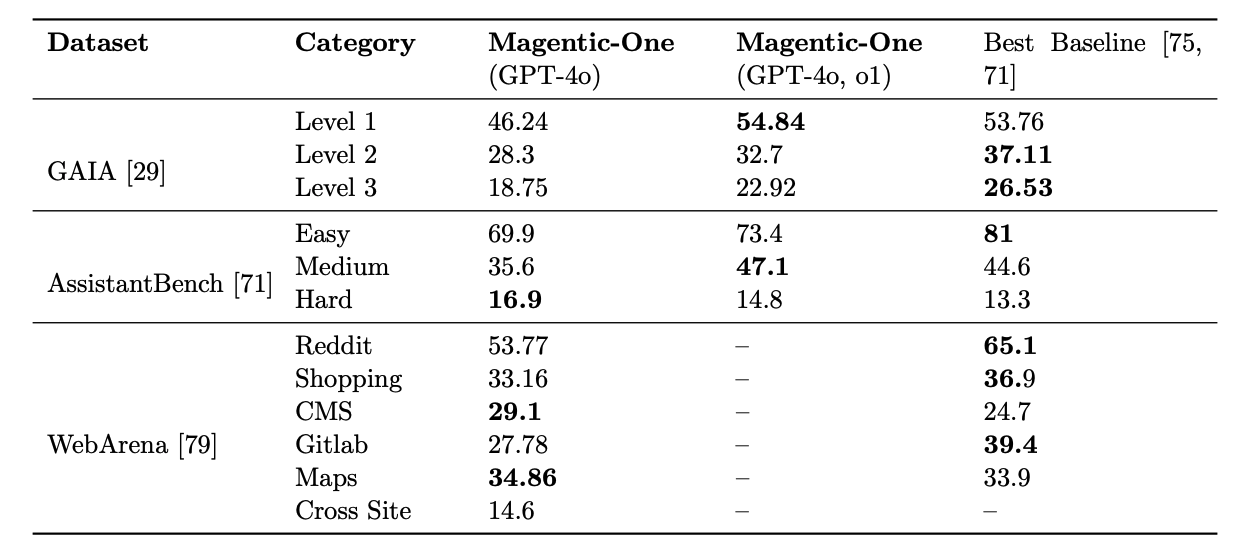
데이터셋 및 결과 설명:
- GAIA:
- GAIA 벤치마크는 세 가지 난이도(Level 1, Level 2, Level 3)로 구성됩니다.
- Magnetic-One (GPT-4o, o1) 설정은 모든 레벨에서 Best Baseline보다 높은 점수를 기록하고 있습니다. 예를 들어, Level 1에서 54.84를 기록하여 Best Baseline의 53.76보다 높은 성과를 보입니다.
- AssistantBench:
- AssistantBench는 난이도에 따라 Easy, Medium, Hard로 나뉩니다.
- Magnetic-One (GPT-4o, o1) 설정은 Medium 난이도에서 47.1로 Best Baseline의 44.6보다 높은 성과를 기록하였지만, Easy와 Hard에서는 Best Baseline에 미치지 못했습니다. Easy에서는 73.4로 Best Baseline 81보다 낮으며, Hard에서도 14.8로 Best Baseline 13.3에 비해 다소 높은 성과를 보였습니다.
- WebArena:
- WebArena는 다양한 주제 영역(Reddit, Shopping, CMS, Gitlab, Maps, Cross Site)으로 나뉘어 있으며, 각 영역에서의 성과가 기록되어 있습니다.
- Magnetic-One은 Reddit 영역에서 53.77을 기록하며 Best Baseline 65.1보다 낮습니다. 나머지 영역에서도 일부 Best Baseline보다 낮은 성과를 기록하고 있습니다.
요약:
- Magnetic-One은 GAIA 벤치마크에서 우수한 성과를 보였으며, 특히 GPT-4o, o1 설정에서 Best Baseline을 초과하는 결과를 보여줍니다.
- AssistantBench에서는 난이도에 따라 성과 차이가 있으며, Medium에서는 Best Baseline을 초과하였지만 Easy와 Hard에서는 약간 미치지 못합니다.
- WebArena에서는 Best Baseline보다 낮은 성과를 기록한 영역이 많습니다.
오류 분석
- 실험 과정에서 발생한 오류를 분석한 결과, 작업 재실행의 비효율성, 방향 설정 실패, 지속적인 오류 무시 등이 주요 문제점으로 드러났습니다. 이러한 오류들은 오케스트레이터의 계획 수정 및 각 에이전트의 협력 과정에서 발생한 것으로, 향후 개선의 필요성을 시사합니다.
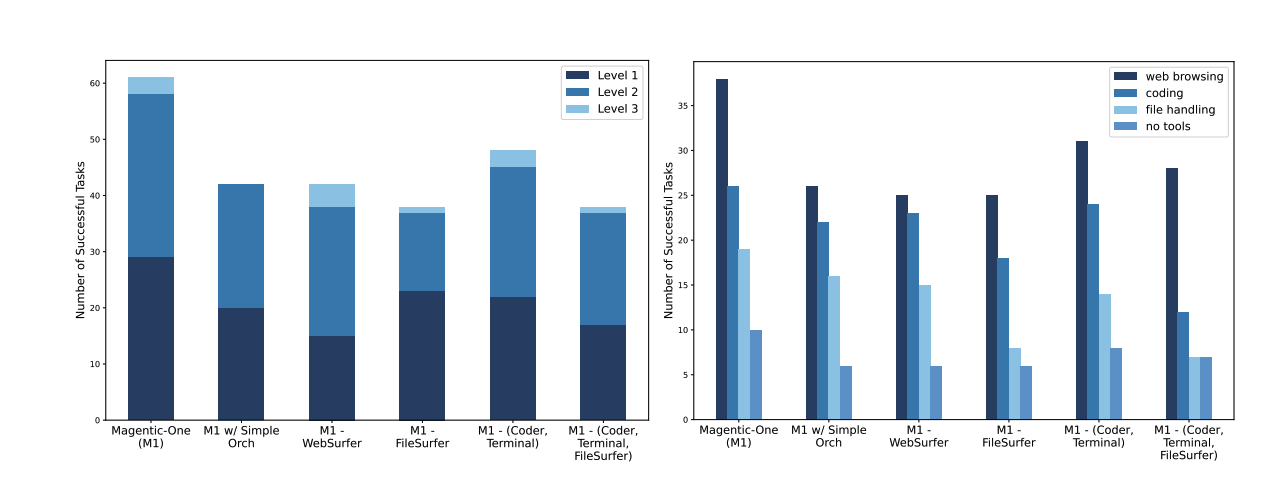
왼쪽 그래프 (난이도 레벨별 성능)
- Y축: 성공한 작업의 수를 나타냅니다.
- X축: Magnetic-One의 다양한 절단(변형) 설정입니다.
- 색상: 각 색상은 난이도 레벨(Level 1, Level 2, Level 3)을 나타냅니다.
- 결과:
- Magnetic-One (M1) 설정에서 가장 높은 성공한 작업 수를 기록하고 있으며, 특히 모든 레벨에서 고르게 높은 성능을 보입니다.
- M1 w/ Simple Orchestrator는 기본 Orchestrator 대신 단순화된 Orchestrator를 사용한 경우로, 성능이 전체적으로 감소했습니다.
- M1 - WebSurfer, M1 - FileSurfer, M1 - (Coder, Terminal) 등의 절단 설정은 각 에이전트를 하나씩 제거한 경우이며, 이러한 경우에도 성능이 전반적으로 감소했습니다.
- 모든 에이전트가 포함된 설정이 최고 성능을 보이는 것으로 보아, 모든 에이전트가 최상의 성능을 달성하는 데 필수적임을 보여줍니다.
오른쪽 그래프 (필요한 기능별 성능)
- Y축: 성공한 작업의 수를 나타냅니다.
- X축: Magnetic-One의 다양한 절단(변형) 설정입니다.
- 색상: 각 기능을 나타냅니다 (웹 브라우징, 코딩, 파일 처리, 도구 없이 수행하는 작업).
- 결과:
- Magnetic-One (M1) 설정이 모든 기능에서 가장 높은 성능을 기록하고 있습니다.
- Web browsing과 coding이 많은 작업에서 필수적인 기능으로 보이며, 특히 Web browsing은 가장 큰 성능 차이를 보입니다.
- 특정 기능을 수행하는 데 필요한 에이전트가 제거되면, 해당 기능과 관련된 성능이 크게 감소합니다.
- 예를 들어, WebSurfer가 제거되면 웹 브라우징 관련 성능이 크게 줄어듭니다.
요약
- 모든 에이전트가 포함된 Magnetic-One 설정이 가장 우수한 성능을 보이며, 모든 작업을 수행하기 위해 다양한 기능이 필요합니다.
- Orchestrator의 복잡도가 성능에 영향을 미치며, 단순화된 Orchestrator를 사용할 경우 성능이 감소합니다.
- 각각의 에이전트(WebSurfer, FileSurfer 등)가 특정 기능에 중요한 역할을 하기 때문에, 에이전트를 제거하면 성능 저하가 발생합니다.
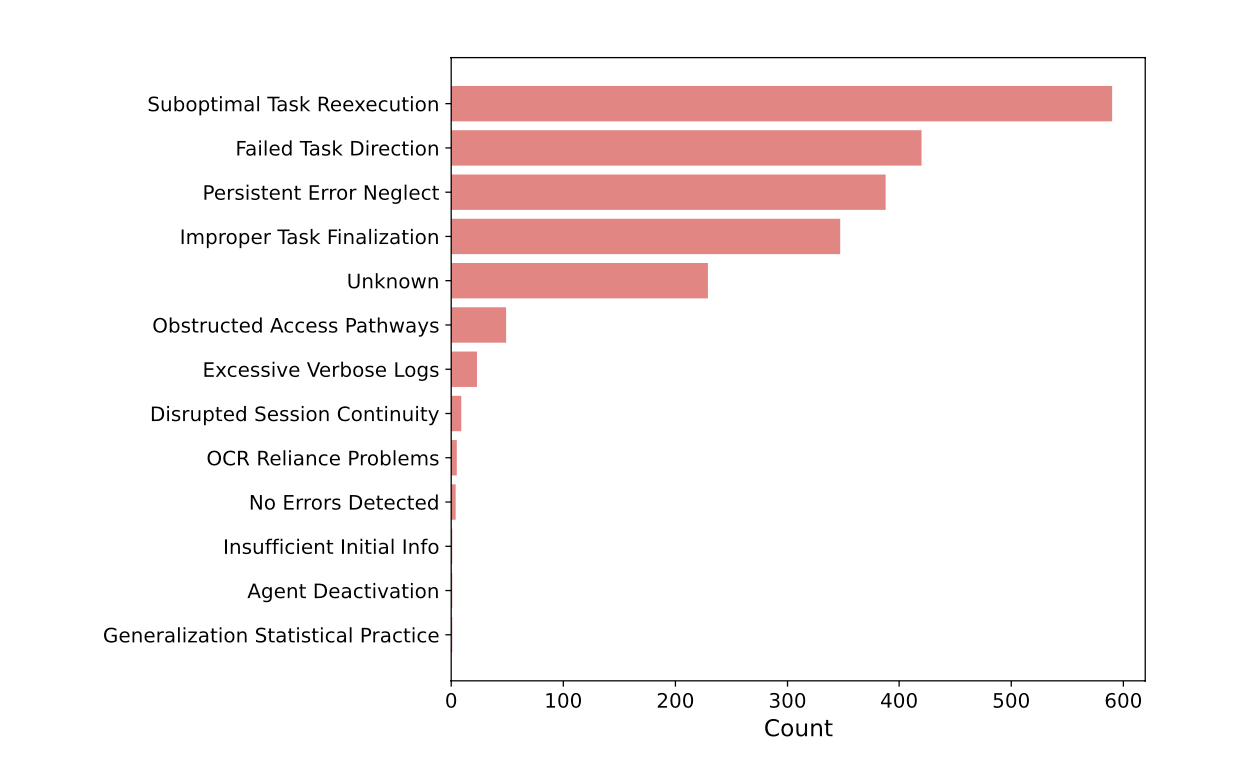
- Suboptimal Task Reexecution (비효율적 작업 재실행):
- 이 오류는 의미 있는 진행 없이 작업을 반복하는 경우를 나타냅니다.
- 시스템이 이전 결과에 따라 전략을 조정하지 못할 때 발생합니다. 예를 들어, Orchestrator가 시스템 응답을 확인하지 않고 작업을 반복적으로 제출하거나, 에이전트가 서버가 다운된 상태에서 반복적으로 요청을 보내는 경우입니다.
- 이러한 상황은 전략적 유연성의 부족을 반영하며, 불필요한 리소스 소비로 이어집니다.
- Failed Task Direction (작업 지시 실패):
- 이 오류는 에이전트 간의 의사소통 문제와 혼선을 초래하는 작업 방향 실패를 나타냅니다.
- 에이전트가 할당된 목표를 제대로 이해하거나 실행하지 못해 작업이 잘못 수행됩니다. 예를 들어, 명확하지 않은 지시로 인해 두 에이전트가 동일한 작업을 중복해서 처리하거나, 에이전트가 목표를 오해하여 구식 정보나 관련 없는 정보를 추구하는 경우가 있습니다.
- 이는 작업의 비효율성을 초래하며, 리소스가 낭비되는 결과를 가져옵니다.
- Persistent Error Neglect (지속적인 오류 무시):
- 이 오류는 반복적인 오류가 해결되지 않은 상태로 유지되는 상황을 설명합니다.
- 권한 없는 접근 시도나 API 실패와 같은 오류가 해결되지 않고 반복적으로 발생하며, 이는 작업 완료를 방해합니다.
- 이러한 반복적인 오류 무시는 오류 처리 메커니즘의 부재를 나타내며, 효과적인 작업 진행을 방해합니다.
6. 논의
다중 에이전트 패러다임
Magentic-One의 다중 에이전트 패러다임은 단일 에이전트로는 처리하기 어려운 복잡한 작업을 해결하는 데 있어 효과적입니다. 각 에이전트가 고유의 역할을 담당하고 협력하여 문제를 해결함으로써, 복잡한 시나리오에서도 높은 성능을 발휘할 수 있었습니다.
한계
- 정확성 중심의 평가:
- Magnetic-One의 성능 평가가 최종 결과의 정확성만을 기준으로 이루어졌습니다. 이는 측정이 용이하다는 장점이 있지만, 비용, 지연 시간, 사용자 선호도 및 가치와 같은 중요한 요소들을 간과할 수 있습니다.
- 예를 들어, 완벽하게 정확한 답변이라도 너무 늦게 도착하거나 비용이 높다면 가치를 잃을 수 있습니다. 이와 같이 주관적이거나 열린 작업을 평가하는 새로운 평가 방식이 필요합니다.
- 높은 비용과 지연 시간:
- Magnetic-One은 대부분의 문제를 해결하기 위해 수십 번의 반복과 LLM 호출이 필요하며, 이는 상당한 비용과 시간을 초래할 수 있습니다.
- 이러한 비용을 줄이기 위해 작은 로컬 모델을 사용하거나 사람의 개입을 통한 비용 절감이 제안됩니다.
- 제한된 멀티모달 처리 능력:
- Magnetic-One은 모든 유형의 미디어를 처리할 수 있는 능력이 부족합니다. 예를 들어, WebSurfer는 온라인 비디오를 볼 수 없으며, FileSurfer는 모든 문서를 Markdown으로 변환하여 이미지나 레이아웃과 관련된 질문에 답할 수 없습니다.
- 이를 개선하기 위해 Audio 및 VideoSurfer 에이전트를 추가하여 오디오 및 비디오 처리 작업을 수행할 수 있는 기능을 확장할 필요가 있습니다.
- 제한된 작업 수행 범위:
- Magnetic-One의 에이전트는 일반적인 작업 수행을 위한 도구만을 제공받았으며, 특정 작업(예: 웹페이지에서 항목 위로 마우스를 올리거나 드래그 및 크기 조절)이 불가능합니다.
- 장기적으로 다양한 도구 사용을 표준화하고, 운영 체제와 애플리케이션을 더 잘 활용할 수 있도록 개선될 필요가 있습니다.
- 제한된 코딩 능력:
- Magnetic-One의 Coder 에이전트는 단순하게 각 요청에 대해 새로운 Python 프로그램을 작성합니다. 코드 디버깅이 필요한 경우 기존 코드의 일부를 수정하기보다는 전체 코드를 새로 작성해야 하며, 이는 복잡한 코드베이스에는 적합하지 않습니다.
- Jupyter Notebook 같은 환경에서 개별 셀을 추가해가며 작업할 수 있도록 개선하면, 코드 재사용이 더 용이할 것입니다.
- 고정된 팀 구성:
- Magnetic-One은 Orchestrator, WebSurfer, FileSurfer, Coder, Computer Terminal의 다섯 에이전트로 구성되며, 에이전트가 고정되어 있습니다.
- 작업에 따라 에이전트를 동적으로 추가하거나 제거할 수 있다면, 불필요한 에이전트가 오케스트레이터의 집중력을 분산시키거나 필요한 전문성을 더할 수 있을 것입니다.
- 학습의 한계:
- Magnetic-One은 단일 작업 시도 내에서만 전략을 조정할 수 있으며, 이러한 학습 결과를 이후의 작업에 적용하지 못합니다.
- 특히 WebArena와 같은 벤치마크에서는 유사한 하위 작업이 반복되는데, 매번 해결 방법을 재발견해야 하므로 비효율적입니다. 이를 해결하기 위해 장기 메모리를 도입하는 것이 중요합니다.
7. 결론
Magentic-One은 복잡한 작업을 해결하기 위한 일반주의 다중 에이전트 시스템으로서, 다양한 도구와 에이전트를 통해 복잡한 문제를 성공적으로 해결할 수 있는 가능성을 보여주고 있습니다. 실험 결과와 분석을 통해 Magentic-One은 특히 다중 에이전트 협력을 통한 계획 수립과 오류 복구에서 뛰어난 성능을 발휘한다는 것을 확인했습니다. 향후 개선을 통해 더욱 다양한 작업을 효과적으로 처리할 수 있는 시스템으로 발전할 가능성이 큽니다.
8. 통계적 방법론
Magentic-One의 실험 결과 분석에는 다양한 통계적 방법이 사용되었습니다. 각 벤치마크에서의 성능 평가와 에이전트 간 상호작용의 영향을 정량적으로 평가하여, Magentic-One의 장단점을 명확히 파악할 수 있었습니다. 이러한 통계적 분석은 향후 시스템 개선을 위한 중요한 자료로 활용될 것입니다.
9. 기능에서 범주 매핑
Magentic-One의 각 기능은 특정 작업 범주에 매핑될 수 있습니다. 예를 들어, 웹서퍼는 정보 수집 범주에 속하며, 파일서퍼는 파일 분석 범주에 속합니다. 이러한 범주 매핑은 각 에이전트의 역할을 명확히 정의하고, 작업 수행 과정에서의 협력 구조를 보다 효율적으로 설계하는 데 도움을 줍니다.
10. 오류 분석 코드북
실험 과정에서 발생한 오류를 체계적으로 분석하기 위해 오류 분석 코드북이 사용되었습니다. 이 코드북은 오류의 원인을 분류하고, 각 오류에 대한 대응 방안을 제시함으로써 향후 시스템 개선에 필요한 자료를 제공합니다. 오류 분석을 통해 발견된 문제들은 Magentic-One의 신뢰성과 효율성을 높이기 위한 중요한 개선 과제로 다루어질 것입니다.
참고 자료 및 리더보드
https://gaia-benchmark-leaderboard.hf.space/
Gradio
Copy the following snippet to cite these results @misc{mialon2023gaia, title={GAIA: a benchmark for General AI Assistants}, author={Grégoire Mialon and Clémentine Fourrier and Craig Swift and Thomas Wolf and Yann LeCun and Thomas Scialom}, year={2023}, e
gaia-benchmark-leaderboard.hf.space
https://docs.google.com/spreadsheets/d/1M801lEpBbKSNwP-vDBkC_pF7LdyGU1f_ufZb_NWNBZQ/edit?gid=0#gid=0
X-WebArena-Leaderboard
ABCDEFGHIRelease DateOpen?Model Size (billion)ModelSuccess Rate (%)Result SourceWorkTrajNote08/2024✗UnknownJace.AI57.1Reported by zetalabs.aihttps://www.jace.ai/Action description + ScreenshotsNote from the developer of the work, see the comment of the c
docs.google.com
https://huggingface.co/spaces/AssistantBench/leaderboard
Leaderboard - a Hugging Face Space by AssistantBench
huggingface.co
논문 : https://www.microsoft.com/en-us/research/uploads/prod/2024/11/Magentic-One.pdf
'[AI] > 논문 리뷰' 카테고리의 다른 글
| DeepSeek 알아보기 - 논문 전문 한글 번역 (1) | 2025.02.04 |
|---|---|
| 한국어 특화 모델 EXAONE 논문 리뷰 (2) | 2024.11.17 |