
논문 출처 : DEEPSEEK
최근 가장 핫한 주제는 deepseek라고 생각됩니다. 그래서 논문을 우선 읽어보도록 하겠습니다!!
번역/의역 작업을 하면서 틀린 부분이 있을 수 있으니 흐름을 파악하는 용도로만 보시고
긴가민가한 부분은 원문을 체크해주세요
논문의 순서대로 번역을 진행했으며 가장 하단에 각 부분의 요약을 작성했습니다.
초록 (Abstract)
우리는 우리의 첫 번째 세대 추론 모델인 DeepSeek-R1-Zero와 DeepSeek-R1을 소개합니다.
DeepSeek-R1-Zero는 감독 학습 기반 미세 조정(SFT, Supervised Fine-Tuning) 없이 대규모 강화 학습(RL, Reinforcement Learning)을 통해 훈련된 모델로, 뛰어난 추론 능력(reasoning capabilities)을 보여줍니다. RL 과정을 거치면서 DeepSeek-R1-Zero는 자연스럽게 강력하고 흥미로운 추론 행동들을 학습합니다.
그러나 DeepSeek-R1-Zero는 가독성(readability) 부족과 언어 혼합(language mixing) 문제와 같은 한계를 가지고 있습니다. 이러한 문제를 해결하고 추론 성능을 더욱 향상시키기 위해, 우리는 다단계 훈련(multi-stage training)과 콜드 스타트(cold-start) 데이터를 RL 이전 단계에서 활용한 DeepSeek-R1을 개발하였습니다.
DeepSeek-R1은 다양한 추론 작업에서 OpenAI o1-1217과 동등한 성능을 달성하였습니다.
연구 커뮤니티를 지원하기 위해, 우리는 DeepSeek-R1-Zero, DeepSeek-R1뿐만 아니라 Qwen 및 Llama 기반으로 DeepSeek-R1을 증류(distillation)한 6개의 밀집 모델(dense models)(1.5B, 7B, 8B, 14B, 32B, 70B)을 오픈 소스로 공개할 예정입니다.

목차
1. 서론
최근 LLM의 발전과 함께, 추론 능력을 향상시키기 위한 다양한 접근법이 연구되고 있습니다. 이 논문에서는 강화 학습을 통해 지도 학습 없이도 LLM이 추론 능력을 개발할 수 있는지를 탐구합니다.
2. 접근 방법
2.1 개요
DeepSeek-R1-Zero와 DeepSeek-R1의 개발 과정을 소개합니다.
2.2 DeepSeek-R1-Zero: 기본 모델에 대한 강화 학습
- 2.2.1 강화 학습 알고리즘: 대규모 강화 학습을 통해 모델을 훈련합니다.
- 2.2.2 보상 모델링: 정확도와 형식에 기반한 보상 함수를 설계합니다.
- 2.2.3 훈련 템플릿: 모델의 추론 과정을 구조화하기 위한 템플릿을 사용합니다.
- 2.2.4 성능 및 자기 진화 과정: 모델의 성능과 학습 중 발견된 '아하 모먼트'를 분석합니다.
2.3 DeepSeek-R1: 콜드 스타트와 함께하는 강화 학습
- 2.3.1 콜드 스타트: 초기 데이터를 사용하여 모델의 초기 성능을 향상시킵니다.
- 2.3.2 추론 지향 강화 학습: 추론 능력을 강화하기 위한 강화 학습 전략을 적용합니다.
- 2.3.3 거부 샘플링 및 지도 학습: 잘못된 추론을 배제하고 모델을 미세 조정합니다.
- 2.3.4 모든 시나리오를 위한 강화 학습: 다양한 시나리오에서 모델의 성능을 향상시킵니다.
2.4 증류: 작은 모델에 추론 능력 부여
대규모 모델의 지식을 작은 모델에 전달하여 효율적인 추론 능력을 갖추도록 합니다.
3. 실험
3.1 DeepSeek-R1 평가
다양한 벤치마크를 통해 모델의 성능을 평가합니다.
3.2 증류 모델 평가
증류된 작은 모델의 성능을 분석합니다.
4. 토론
4.1 증류 vs. 강화 학습
두 접근법의 장단점을 비교합니다.
4.2 실패한 시도들
연구 과정에서 직면한 도전과 실패 사례를 공유합니다.
5. 결론, 한계 및 향후 연구
연구의 주요 발견을 요약하고, 현재 한계와 향후 연구 방향을 제시합니다.
이 논문은 강화 학습을 통해 LLM의 추론 능력을 향상시키는 새로운 방법을 제시하며, 향후 연구에 중요한 기여를 합니다.
1. 서론 (Introduction)
최근 몇 년간 대형 언어 모델(LLM)은 빠르게 발전하며, 인공지능 일반화(AGI)에 가까워지고 있습니다 (Anthropic, 2024; Google, 2024; OpenAI, 2024a). 최근에는 사후 훈련(post-training)이 전체 훈련 과정에서 중요한 요소로 떠오르고 있습니다. 사후 훈련은 추론 작업에서의 정확도를 향상시키고, 사회적 가치와 정렬되며, 사용자 선호도에 적응하는 동시에, 사전 훈련(pre-training)에 비해 상대적으로 적은 계산 자원을 필요로 한다는 점에서 주목받고 있습니다.
추론 능력과 관련하여, OpenAI의 o1(OpenAI, 2024b) 모델 시리즈는 최초로 체인 오브 싱킹(Chain-of-Thought) 추론 과정을 늘려서 추론 중(inference-time) 성능을 확장하는 방법을 도입했습니다. 이 접근 방식은 수학, 코딩, 과학적 추론 등 다양한 추론 작업에서 상당한 성능 향상을 이루었습니다. 하지만 효과적인 테스트 중 확장(test-time scaling)의 문제는 여전히 연구 커뮤니티에서 해결해야 할 난제로 남아 있습니다.
이전 연구들은 프로세스 기반 보상 모델(process-based reward models) (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023), 강화 학습(Kumar et al., 2024), 몬테카를로 트리 탐색(Monte Carlo Tree Search) 및 빔 탐색(Beam Search) (Feng et al., 2024; Trinh et al., 2024; Xin et al., 2024) 등의 다양한 접근법을 시도했습니다. 하지만 이 방법들 중 어느 것도 OpenAI의 o1 모델 시리즈에 필적하는 일반적인 추론 성능을 달성하지 못했습니다.
본 논문에서는 순수한 강화 학습(RL)만을 사용하여 LLM의 추론 능력을 향상시키는 첫 번째 연구를 수행합니다. 우리의 목표는 감독 학습 데이터(supervised data) 없이 LLM이 스스로 진화하여 추론 능력을 개발할 수 있는 가능성을 탐색하는 것입니다. 이를 위해, 우리는 DeepSeek-V3-Base 모델을 기반 모델로 사용하고, GRPO (Shao et al., 2024) 프레임워크를 활용하여 추론 성능을 향상시켰습니다.
훈련 과정에서, DeepSeek-R1-Zero 모델은 자연스럽게 강력하고 흥미로운 추론 행동들을 학습했습니다. 수천 번의 RL 단계를 거친 후, DeepSeek-R1-Zero는 추론 벤치마크에서 뛰어난 성능을 보였습니다. 예를 들어, AIME 2024 테스트에서 pass@1 점수가 15.6%에서 71.0%로 상승했으며, 다수결 투표(majority voting)를 적용하면 86.7%까지 증가하여 OpenAI-o1-0912와 동일한 성능을 기록했습니다.
그러나 DeepSeek-R1-Zero는 가독성이 낮고, 언어 혼합(language mixing) 문제가 발생하는 등의 한계를 보였습니다. 이러한 문제를 해결하고 추론 성능을 더욱 향상시키기 위해, 우리는 소량의 콜드 스타트(cold-start) 데이터를 포함한 다단계 훈련(multi-stage training) 파이프라인을 도입한 DeepSeek-R1을 개발했습니다. 구체적으로, 먼저 수천 개의 콜드 스타트 데이터를 수집하여 DeepSeek-V3-Base 모델을 미세 조정(fine-tuning)했습니다. 이후, DeepSeek-R1-Zero와 유사한 방식으로 추론 중심의 RL(reasoning-oriented RL)을 수행했습니다. RL 과정에서 수렴이 가까워지면, RL 체크포인트에서 거부 샘플링(rejection sampling)을 수행하여 새로운 SFT 데이터(supervised fine-tuning data)를 생성하고, DeepSeek-V3의 지도 학습 데이터를 결합하여 (글쓰기, 사실 기반 질의응답, 자기 인식 분야) 다시 DeepSeek-V3-Base 모델을 훈련했습니다. 새로운 데이터로 미세 조정을 마친 후, 모든 시나리오의 프롬프트를 고려한 추가 RL 과정을 거쳐 최종적으로 DeepSeek-R1 체크포인트를 얻었습니다. 이 모델은 OpenAI-o1-1217과 동등한 성능을 달성했습니다.
추가적으로, 우리는 DeepSeek-R1을 더 작은 밀집 모델(dense models)로 증류(distillation)하는 실험을 진행했습니다. Qwen2.5-32B (Qwen, 2024b)를 기반 모델로 하여 DeepSeek-R1에서 직접 증류하는 것이, Qwen2.5-32B에 RL을 적용하는 것보다 더 나은 성능을 보였습니다. 이는 대규모 모델이 발견한 추론 패턴이 추론 능력 향상에 중요한 역할을 한다는 것을 보여줍니다. 우리는 증류된 Qwen 및 Llama (Dubey et al., 2024) 모델을 오픈 소스로 공개할 예정입니다. 특히, 증류된 14B 모델은 최첨단 오픈 소스 모델인 QwQ-32B-Preview(Qwen, 2024a)를 훨씬 뛰어넘는 성능을 기록했으며, 증류된 32B 및 70B 모델은 밀집 모델 중에서 새로운 추론 벤치마크 기록을 세웠습니다.
1.1. 기여 (Contributions)
사후 훈련(Post-Training): 기반 모델에서 대규모 강화 학습 적용
- 우리는 감독 학습 기반 미세 조정(SFT, Supervised Fine-Tuning) 없이 기반 모델에 강화 학습(RL, Reinforcement Learning)을 직접 적용했습니다.
- 이를 통해 모델이 체인 오브 싱킹(CoT, Chain-of-Thought)을 탐색하며 복잡한 문제를 해결할 수 있도록 했으며, DeepSeek-R1-Zero를 개발할 수 있었습니다.
- DeepSeek-R1-Zero는 자기 검증(self-verification), 반성(reflection), 그리고 긴 CoT 생성 능력 등을 보여주며 연구 커뮤니티에서 중요한 이정표를 남겼습니다.
- 특히, 이 연구는 LLM의 추론 능력을 순수한 RL만으로 유도할 수 있음을 검증한 최초의 오픈 연구(open research)로, SFT 없이도 가능하다는 점에서 큰 돌파구를 마련했습니다.
- 우리는 DeepSeek-R1을 개발하기 위한 훈련 파이프라인을 소개합니다.
- 이 파이프라인은 향상된 추론 패턴을 발견하고 인간의 선호도에 맞추기 위해 2단계의 RL을 수행하며,
- 모델의 추론 및 비추론 능력의 시드를 제공하는 2단계의 SFT를 포함합니다.
- 이 파이프라인은 산업계에서도 더 나은 모델을 만드는 데 도움이 될 것으로 기대됩니다
증류(Distillation): 작은 모델도 강력할 수 있다
- 우리는 대형 모델이 학습한 추론 패턴을 작은 모델에 증류(distillation)하여,
- 작은 모델이 강화 학습을 통해 직접 학습한 것보다 더 나은 성능을 달성할 수 있음을 입증했습니다.
- 오픈 소스로 공개될 DeepSeek-R1과 그 API는 연구 커뮤니티에서 향후 더 나은 작은 모델을 증류하는 데 기여할 것입니다.
- DeepSeek-R1이 생성한 추론 데이터를 활용하여 여러 개의 밀집 모델(dense models)을 미세 조정했습니다.
- 실험 결과, 증류된 작은 밀집 모델이 벤치마크에서 매우 뛰어난 성능을 보였습니다.
- DeepSeek-R1-Distill-Qwen-7B는 AIME 2024 테스트에서 55.5%를 기록하며 QwQ-32B-Preview를 초월하는 성능을 보였습니다.
- DeepSeek-R1-Distill-Qwen-32B는 AIME 2024에서 72.6%, MATH-500에서 94.3%, LiveCodeBench에서 57.2%를 기록하며,
- 이전 오픈소스 모델을 크게 뛰어넘고, OpenAI o1-mini에 필적하는 성능을 달성했습니다.
- 우리는 Qwen2.5 및 Llama3 시리즈 기반의 증류 모델(1.5B, 7B, 8B, 14B, 32B, 70B)의 체크포인트를 오픈 소스로 공개할 예정입니다.
1.2. 평가 결과 요약 (Summary of Evaluation Results)
1) 추론 작업(Reasoning tasks)
- DeepSeek-R1은 AIME 2024 테스트에서 79.8%의 Pass@1 점수를 기록하여 OpenAI-o1-1217을 근소하게 상회하였습니다.
- MATH-500 벤치마크에서는 97.3%라는 높은 성능을 기록, OpenAI-o1-1217과 동급이며, 다른 모델들보다 월등히 뛰어난 결과를 보였습니다.
- 코딩 관련 작업에서는 전문가 수준의 코드 생성 능력을 보여주었으며,
- Codeforces에서 2,029 Elo 점수를 기록,
- 경쟁에 참가한 인간 참가자의 96.3%를 능가하는 성능을 보였습니다.
- 엔지니어링 관련 작업에서는 DeepSeek-R1이 DeepSeek-V3보다 더 나은 성능을 기록,
- 실제 개발자들의 작업에 도움이 될 수 있는 수준의 성능을 입증하였습니다.
2) 지식(Knowledge)
- DeepSeek-R1은 MMLU, MMLU-Pro, GPQA Diamond 등의 지식 평가 벤치마크에서 탁월한 성능을 보였습니다.
- MMLU에서 90.8%, MMLU-Pro에서 84.0%, GPQA Diamond에서 71.5%를 기록하여,
- DeepSeek-V3보다 훨씬 뛰어난 성능을 보였습니다.
- OpenAI-o1-1217보다는 약간 낮은 성능을 보였으나,
- 다른 비공개 모델(closed-source models)보다 훨씬 뛰어난 결과를 기록하였습니다.
- MMLU에서 90.8%, MMLU-Pro에서 84.0%, GPQA Diamond에서 71.5%를 기록하여,
- 사실 기반 질의응답(factual QA) 벤치마크인 SimpleQA에서 DeepSeek-R1은 DeepSeek-V3를 초월하는 성능을 보였습니다.
- OpenAI o1 모델이 4o 모델보다 더 우수한 성능을 보이는 것과 유사한 추세를 나타냈습니다.
3) 기타 작업 (Others)
- 창의적 글쓰기(creative writing), 일반 질문 응답(QA), 편집(editing), 요약(summarization) 등 다양한 작업에서도 DeepSeek-R1은 뛰어난 성능을 보였습니다.
- AlpacaEval 2.0에서 87.6%의 길이 제어(length-controlled) 승률(win-rate)을 기록하였으며,
- Arena-Hard 벤치마크에서는 92.3%의 승률을 달성하여,
- 비시험(시험이 아닌) 지향적 질의(non-exam-oriented queries)에 대한 강력한 처리 능력을 보여주었습니다.
- 긴 문맥(long-context) 이해가 필요한 작업에서도 DeepSeek-R1은 뛰어난 성능을 기록하였으며,
- DeepSeek-V3보다 훨씬 우수한 결과를 보이며 장문 이해(long-context understanding) 벤치마크에서 우위를 점했습니다.
2. 접근 방법 (Approach)
2.1 개요 (Overview)
기존 연구들은 모델 성능을 향상시키기 위해 대량의 감독 학습(Supervised Learning) 데이터에 의존해 왔습니다.
하지만 본 연구에서는 강화 학습(RL, Reinforcement Learning)을 대규모로 적용하면 감독 학습 기반 미세 조정(SFT, Supervised Fine-Tuning) 없이도
추론 능력을 크게 향상시킬 수 있음을 입증합니다.
또한, 소량의 콜드 스타트(cold-start) 데이터를 추가하면 성능이 더욱 향상될 수 있음을 보입니다.
이 섹션에서는 다음 내용을 다룹니다:
- DeepSeek-R1-Zero: SFT 데이터를 전혀 사용하지 않고, 강화 학습을 기반 모델(Base Model)에 직접 적용한 모델.
- DeepSeek-R1: 수천 개의 긴 체인 오브 싱킹(CoT, Chain-of-Thought) 예제로 미세 조정된 체크포인트에서 RL을 시작한 모델.
- 추론 능력 증류(Distillation): DeepSeek-R1의 추론 능력을 작은 밀집 모델(Dense Model)에 증류하는 방법.
2.2 DeepSeek-R1-Zero: 기반 모델에서의 강화 학습 (Reinforcement Learning on the Base Model)
강화 학습은 추론 작업에서 매우 효과적인 방식임이 입증되었습니다 (Shao et al., 2024; Wang et al., 2023).
하지만 기존 연구들은 대량의 감독 학습 데이터에 의존했으며,
이러한 데이터는 수집하는 데 많은 시간과 비용이 소요됩니다.
본 연구에서는 LLM이 전혀 감독 학습 데이터를 사용하지 않고도
강화 학습을 통해 자기 진화(self-evolution) 방식으로 추론 능력을 개발할 수 있는지 탐구합니다.
이 섹션에서는 먼저 우리의 강화 학습 알고리즘을 간략히 소개한 뒤,
흥미로운 실험 결과를 공유함으로써 연구 커뮤니티에 유용한 인사이트를 제공하고자 합니다.
2.2.1 강화 학습 알고리즘 (Reinforcement Learning Algorithm)
그룹 상대 정책 최적화 (Group Relative Policy Optimization, GRPO)
강화 학습의 훈련 비용을 절감하기 위해,
우리는 그룹 상대 정책 최적화(GRPO, Group Relative Policy Optimization) (Shao et al., 2024) 기법을 채택하였습니다.
GRPO는 일반적인 강화 학습에서 사용되는 비평자 모델(critic model)을 제거하는 대신,
그룹 점수(group scores)에서 베이스라인을 추정하는 방식으로 동작합니다.
구체적인 방법은 다음과 같습니다:
- 각 질문 q에 대해,
- GRPO는 기존 정책(𝜋𝜃𝑜𝑙𝑑)에서 생성된 출력 그룹 {𝑜1, 𝑜2, · · · , 𝑜𝐺}을 샘플링합니다.
- 이후, 다음 목표(objective)를 최대화하도록 정책 모델(𝜋𝜃)을 최적화합니다.
(이후 논문에서는 이 수식을 포함하여 자세한 설명이 이어집니다.)
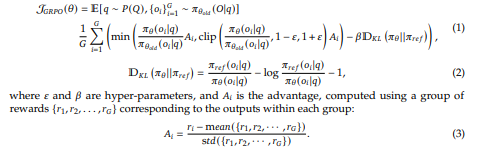

사용자와 어시스턴트 간의 대화. 사용자가 질문을 하면 어시스턴트가 이를 해결한다.
어시스턴트는 먼저 마음속에서(reasoning process in the mind) 추론 과정을 생각한 후,
사용자에게 답변을 제공한다.
추론 과정과 답변은 각각 <think> </think> 및 <answer> </answer> 태그로 감싸진다.
즉, 다음과 같은 형식을 따른다:
<think> 여기에서 추론 과정 </think> <answer> 여기에서 답변 </answer>User: 프롬프트.
Assistant:
Table 1 | DeepSeek-R1-Zero를 위한 템플릿.
훈련 중에는 프롬프트(prompt)가 특정한 추론 문제(specific reasoning question)로 대체된다.
2.2.2. 보상 모델링 (Reward Modeling)
보상(reward)은 훈련 신호(training signal)의 원천이며, 강화 학습(RL)의 최적화 방향을 결정하는 요소입니다.
DeepSeek-R1-Zero를 훈련하기 위해, 규칙 기반(rule-based) 보상 시스템을 채택하였으며,
이는 주로 두 가지 유형의 보상으로 구성됩니다:
- 정확도 보상(Accuracy rewards):
- 정확도 보상 모델은 응답이 정확한지 평가하는 역할을 합니다.
- 예를 들어, 결과가 결정적인(deterministic) 수학 문제의 경우,
- 모델은 반드시 지정된 형식(예: 상자 안에 정답을 기재)으로 최종 답변을 제공해야 합니다.
- 이를 통해 규칙 기반 검증(rule-based verification)을 신뢰할 수 있도록 수행할 수 있습니다.
- 마찬가지로, LeetCode 문제에서는 컴파일러를 사용하여
- 미리 정의된 테스트 케이스(predefined test cases)를 기반으로 모델의 응답을 검증할 수 있습니다.
- 형식 보상(Format rewards):
- 정확도 보상 모델 외에도,
- 형식 보상 모델(format reward model)을 사용하여,
- 모델이 추론 과정(thinking process)을 반드시 <think>와 </think> 태그 사이에 포함하도록 강제합니다.
DeepSeek-R1-Zero를 개발할 때, 결과 기반(outcome-based) 또는 과정 기반(process-based) 신경 보상 모델(neural reward model)은 적용하지 않았습니다.
- 그 이유는 대규모 강화 학습 과정에서 신경 보상 모델이 "보상 해킹(reward hacking)" 문제를 일으킬 가능성이 있기 때문입니다.
- 또한, 보상 모델을 재훈련하는 과정에서 추가적인 학습 리소스가 필요하며, 전체 훈련 파이프라인이 복잡해지는 문제점이 발생할 수 있습니다.
2.2.3. 훈련 템플릿 (Training Template)
DeepSeek-R1-Zero를 훈련하기 위해,
기본 모델(base model)이 지정된 명령(instructions)을 따를 수 있도록 단순한 템플릿을 설계하는 것부터 시작하였습니다.
Table 1에 제시된 것처럼,
이 템플릿에서는 DeepSeek-R1-Zero가 먼저 "추론 과정(reasoning process)"을 생성한 후, "최종 정답(final answer)"을 생성하도록 요구합니다.
우리는 이러한 구조적 형식(structural format)에 대한 제약만 설정하고,
- 반성적 추론(reflective reasoning)을 반드시 수행하도록 강요하거나,
- 특정 문제 해결 전략(problem-solving strategy)을 유도하는 등의 "내용적 편향(content-specific biases)"은 피하였습니다.
이러한 방식은 강화 학습 과정에서 모델이 자연스럽게 학습해 나가는 과정을 정확하게 관찰할 수 있도록 보장하기 위함입니다.
2.2.4. DeepSeek-R1-Zero의 성능, 자기 진화 과정 및 '아하 모먼트(Aha Moment)'
DeepSeek-R1-Zero의 성능 (Performance of DeepSeek-R1-Zero)
- Figure 2는 DeepSeek-R1-Zero가 AIME 2024 벤치마크에서 학습을 진행하는 동안 성능이 어떻게 변화하는지를 보여줍니다.
- 그래프를 보면, 강화 학습이 진행됨에 따라 모델의 성능이 꾸준하고 일관되게 향상되는 것을 확인할 수 있습니다.
- 특히, AIME 2024에서의 평균 pass@1 점수는 훈련 초기 15.6%에서 71.0%까지 대폭 증가하였습니다.
- 이는 결국 OpenAI-o1-0912와 동급의 성능을 달성한 수준입니다.
- 이러한 극적인 성능 향상은, 우리가 사용한 강화 학습 알고리즘이 시간 경과에 따라 모델의 성능을 최적화하는 데 매우 효과적이었음을 보여줍니다.
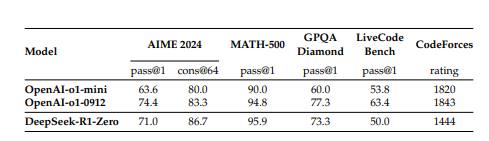
이 표는 DeepSeek-R1-Zero와 OpenAI의 o1 모델(O1-mini, O1-0912)의 추론 관련 성능을 다양한 벤치마크에서 비교한 것입니다.
- AIME 2024 (pass@1): DeepSeek-R1-Zero는 71.0%를 기록하여, OpenAI-o1-0912의 74.4%에 근접한 성능을 보였습니다.
- MATH-500 (pass@1): DeepSeek-R1-Zero는 86.7%를 기록하여, OpenAI-o1-0912의 83.3%보다 높은 성능을 보였습니다.
- GPQA Diamond (pass@1): DeepSeek-R1-Zero는 95.9%를 기록하여, OpenAI-o1-0912의 94.8%보다 높은 점수를 획득하였습니다.
- LiveCode Bench (pass@1): DeepSeek-R1-Zero는 73.3%를 기록하여, OpenAI-o1-0912의 77.3%보다 낮은 성능을 보였습니다.
- CodeForces (rating): DeepSeek-R1-Zero는 1444점을 기록하여, OpenAI-o1-0912의 1843점보다 낮은 성능을 보였습니다.

그림 2: 훈련 중 DeepSeek-R1-Zero의 AIME 정확도 변화
이 그래프는 DeepSeek-R1-Zero가 AIME 2024 벤치마크에서 학습하면서 성능이 어떻게 변화하는지를 나타냅니다.
- 각 질문에 대해 16개의 응답을 샘플링하여 전체 평균 정확도를 계산하고, 이를 통해 안정적인 평가를 수행합니다.
- 훈련이 진행됨에 따라 모델의 정확도가 점진적으로 향상되는 것을 확인할 수 있습니다.
DeepSeek-R1-Zero는 미세 조정 데이터(fine-tuning data) 없이도 강력한 추론 능력을 획득할 수 있습니다.
이것은 매우 중요한 성과이며, 모델이 오직 강화 학습(RL)만으로도 학습하고 발전할 수 있음을 보여줍니다.
또한, DeepSeek-R1-Zero의 성능은 다수결 투표(majority voting)를 적용함으로써 더욱 향상될 수 있습니다.
예를 들어, AIME 벤치마크에서 다수결 투표를 적용하면,
- DeepSeek-R1-Zero의 성능은 71.0%에서 86.7%까지 상승하여,
- OpenAI-o1-0912의 성능을 초과하는 결과를 달성합니다.
DeepSeek-R1-Zero가 다수결 투표 없이도 이와 같은 경쟁력을 유지할 수 있다는 점은,
- 모델이 강력한 기초 추론 능력을 보유하고 있으며, 향후 추론 연구에 큰 가능성을 가지고 있음을 시사합니다.
DeepSeek-R1-Zero의 자기 진화(Self-evolution Process)
DeepSeek-R1-Zero의 자기 진화 과정은 강화 학습(RL)이 모델의 추론 능력을 어떻게 자율적으로 향상시킬 수 있는지를 보여주는 흥미로운 사례입니다.
강화 학습을 기반 모델(Base Model)에서 직접 시작함으로써,
감독 학습(Supervised Fine-Tuning)의 영향을 받지 않은 상태에서 모델의 발전 과정을 면밀히 모니터링할 수 있습니다.
이러한 접근 방식은 특히 모델이 시간이 지남에 따라 어떻게 복잡한 추론 작업을 처리하는 능력을 갖추는지에 대한 명확한 관점을 제공합니다.

DeepSeek-R1-Zero의 사고 시간 향상 (Figure 3 분석)
Figure 3에 나타난 것처럼,
- DeepSeek-R1-Zero의 평균 응답 길이(response length)는 강화 학습 과정에서 지속적으로 증가하고 있습니다.
- 이는 외부적인 조정(external adjustments) 없이,
- 모델 자체가 추론 작업을 해결하는 과정에서 사고(thinking) 시간을 자연스럽게 늘려가는 것을 의미합니다.
- 즉, DeepSeek-R1-Zero는 점점 더 복잡한 추론 작업을 해결할 수 있도록 학습하며,
- 테스트 시간 계산(test-time computation)을 활용하여 더욱 깊이 있는 사고 과정을 탐색하고 정제(refine)할 수 있는 능력을 갖추게 됩니다.
- 모델이 생성하는 추론 토큰(reasoning tokens)의 개수는 수백 개에서 수천 개까지 증가할 수 있습니다.
자연스럽게 등장한 고급 추론 행동들
DeepSeek-R1-Zero의 자기 진화 과정에서 가장 주목할 만한 점 중 하나는,
- 테스트 시간 계산량(test-time computation)이 증가함에 따라 더욱 정교한 행동(sophisticated behaviors)이 자연스럽게 등장했다는 점입니다.
이러한 행동에는 다음과 같은 요소들이 포함됩니다:
- 반성(Reflection):
- 모델이 이전 단계를 되돌아보고(revisit) 다시 평가(re-evaluate)하는 능력을 습득합니다.
- 이를 통해, 자신의 추론 과정을 검토하고 수정하는 방식으로 문제 해결 능력을 강화합니다.
- 대체 접근법 탐색(Exploration of Alternative Approaches):
- 모델은 단순히 한 가지 방식으로 문제를 해결하는 것이 아니라, 다양한 해결 전략을 스스로 탐색하게 됩니다.
- 이를 통해 더 창의적이고 효율적인 방식으로 문제를 해결할 가능성이 높아집니다.
이러한 행동들은 강화 학습 환경과의 상호작용(interaction) 과정에서 자발적으로 발생하며,
- 별도로 프로그래밍된(explicitly programmed) 것이 아니라 자연스럽게 학습된(spontaneous development) 결과물입니다.
이러한 자연 발생적 학습(Spontaneous Learning)은 DeepSeek-R1-Zero의 추론 능력을 크게 향상시키며,
- 더 복잡한 작업을 더욱 높은 효율성과 정확도로 해결할 수 있도록 돕습니다.

설명 (Table 3 설명)
이 표는 DeepSeek-R1-Zero의 중간 버전에서 발생한 "아하 모먼트(aha moment)"를 보여줍니다.
- 모델이 문제를 다시 생각(rethink)하며,
- 마치 인간처럼(anthropomorphic tone) 사고하는 모습을 보여줍니다.
- 이 순간은 모델이 스스로 자신의 추론 과정에 대한 문제점을 인식하고 재평가(re-evaluate)하는 과정입니다.
이것은 우리에게도 "아하 모먼트"(붉게 표시된 멘트)이며,
이를 통해 강화 학습이 만들어내는 학습의 힘과 아름다움을 경험할 수 있습니다.
DeepSeek-R1-Zero의 한계점 (Drawbacks of DeepSeek-R1-Zero)
DeepSeek-R1-Zero는 강력한 추론 능력을 보여주며,
예상치 못한 혁신적인(reasoning behaviors) 추론 행동들을 자율적으로 개발할 수 있는 모델입니다.
그러나 몇 가지 한계점이 존재합니다.
예를 들어, DeepSeek-R1-Zero는 다음과 같은 문제점을 겪습니다:
- 가독성 부족(Poor readability):
- 모델이 생성하는 추론 과정이 이해하기 어려운 방식으로 표현되는 경우가 많습니다.
- 언어 혼합(Language mixing):
- 특정 상황에서 다양한 언어가 섞여서 출력되는 문제가 발생합니다.
이를 해결하고 추론 과정을 더 쉽게 읽을 수 있도록(Readability 향상)
또한, 오픈 커뮤니티와 더 효과적으로 공유할 수 있도록
우리는 DeepSeek-R1을 연구하였습니다.
DeepSeek-R1은 인간 친화적인(human-friendly) 콜드 스타트 데이터(cold-start data)를 RL과 함께 활용하는 방법을 도입한 모델입니다.
2.3.1. 콜드 스타트 (Cold Start)
DeepSeek-R1-Zero와 달리, DeepSeek-R1은 초기 RL 훈련의 불안정한 콜드 스타트 단계를 방지하기 위해
소량의 긴 체인 오브 싱킹(CoT, Chain-of-Thought) 데이터를 구축하여 모델을 미세 조정(fine-tune)한 후
초기 RL 액터(actor)로 활용합니다.
이러한 데이터를 수집하기 위해 다양한 접근법을 탐색하였습니다:
- Few-shot prompting을 사용하여 긴 CoT를 예제로 활용
- 반성과 검증(reflection and verification)을 포함한 상세한 답변을 생성하도록 모델을 직접 프롬팅(prompting)
- DeepSeek-R1-Zero의 출력을 읽기 쉬운 형식으로 변환
- 사후 처리(post-processing) 과정에서 인간 주석자(human annotators)를 활용하여 결과를 정제(refining)
이 연구에서는 수천 개의 콜드 스타트 데이터를 수집하여
DeepSeek-V3-Base를 RL 훈련의 시작점으로 미세 조정하였습니다.
DeepSeek-R1-Zero와 비교할 때, 콜드 스타트 데이터의 장점은 다음과 같습니다:
- 가독성(Readability):
- DeepSeek-R1-Zero의 주요 한계 중 하나는 출력 내용이 읽기 어려운 경우가 많다는 점입니다.
- 응답에 여러 언어가 혼합되거나, 마크다운(markdown) 형식이 부족하여 정답을 강조하지 못하는 경우가 발생할 수 있습니다.
- 이에 비해 DeepSeek-R1의 콜드 스타트 데이터는 각 응답의 끝에 요약(summary)을 포함하여 읽기 쉬운 패턴을 설계하였습니다.
- 또한, 사용자가 쉽게 이해할 수 있도록 가독성이 낮은 응답은 필터링하였습니다.
- 출력 형식은 다음과 같이 정의됩니다:
|special_token|<reasoning_process>|special_token|<summary>
- 여기서 reasoning_process는 질의(query)에 대한 체인 오브 싱킹(CoT)을 나타내며,
- summary는 추론 결과를 요약하는 역할을 합니다.
- 가능성(Potential):
- 인간의 사전 지식(human priors)을 활용하여 콜드 스타트 데이터 패턴을 신중하게 설계함으로써,
- DeepSeek-R1-Zero보다 우수한 성능을 달성할 수 있었습니다.
- 우리는 이러한 반복적인(iterative) 학습 과정이 추론 모델을 개선하는 더 나은 방법이라고 믿습니다.
- 인간의 사전 지식(human priors)을 활용하여 콜드 스타트 데이터 패턴을 신중하게 설계함으로써,
2.3.2. 추론 중심 강화 학습 (Reasoning-oriented Reinforcement Learning)
DeepSeek-V3-Base를 콜드 스타트 데이터로 미세 조정한 후,
DeepSeek-R1-Zero에서 사용된 것과 동일한 대규모 강화 학습(RL) 훈련 프로세스를 적용하였습니다.
이 단계에서는 모델의 추론 능력을 강화하는 데 초점을 맞추었습니다.
특히, 수학, 코딩, 과학, 논리적 추론과 같은 명확한 해결책이 존재하는(reasoning-intensive) 문제들에서 성능을 향상시키는 것을 목표로 하였습니다.
훈련 과정에서, CoT 응답이 여러 언어가 혼합되는(language mixing) 문제가 자주 발생한다는 점을 관찰하였습니다.
- 특히, RL 프롬프트가 여러 언어로 이루어진 경우 이러한 현상이 더 두드러졌습니다.
이를 해결하기 위해, RL 훈련 중 "언어 일관성 보상(language consistency reward)"을 도입하였습니다.
- 이 보상은 CoT 내에서 목표(target) 언어의 단어 비율을 계산하여 부여됩니다.
- 실험 결과, 이러한 조정이 모델의 성능을 약간 저하시킬 수는 있지만,
- 출력이 더욱 읽기 쉬워지고(human preference aligned), 사용자의 선호도와 일치한다는 점에서 의미 있는 변화였습니다.
최종적으로, 추론 작업의 정확도 보상(accuracy reward)과 언어 일관성 보상(language consistency reward)을 단순 합산하여 최종 보상을 구성하였습니다.
그리고 이를 바탕으로 RL 훈련을 진행하여, 모델이 추론 작업에서 수렴(convergence)에 도달할 때까지 반복 학습하였습니다.
2.3.3. 거부 샘플링 및 감독 학습 미세 조정 (Rejection Sampling and Supervised Fine-Tuning, SFT)
추론 중심 강화 학습이 수렴한 후,
이전 체크포인트를 활용하여 SFT(Supervised Fine-Tuning) 데이터를 수집하고 다음 훈련 단계에 사용하였습니다.
이 단계에서는 초기 콜드 스타트 데이터가 주로 추론 중심(reasoning-focused)이었던 것과 달리,
- 쓰기(writing), 롤플레잉(role-playing), 기타 일반적인 작업(general-purpose tasks)과 같은 다른 도메인의 데이터도 포함하였습니다.
데이터 생성 및 모델 미세 조정 과정은 다음과 같습니다:
1) 추론 데이터 (Reasoning Data)
- 이전 RL 훈련 단계에서 거부 샘플링(rejection sampling)을 수행하여 추론 데이터셋을 구축하였습니다.
- 이전 단계에서는 규칙 기반 보상(rule-based rewards)을 사용하여 평가할 수 있는 데이터만 포함하였지만,
- 이번에는 추가적인 데이터들을 포함하여 데이터셋을 확장하였습니다.
- 일부 데이터는 생성형 보상 모델(generative reward model)을 사용하여 평가하였습니다.
- 즉, DeepSeek-V3 모델을 활용하여, 정답(ground-truth)과 모델 예측값을 비교하고 평가하는 방식을 도입하였습니다.
- 또한, 모델 출력이 난잡하거나(chaotic) 읽기 어려운 경우
- 언어 혼합(mixed languages), 긴 문단(long paragraphs), 코드 블록(code blocks)을 포함한 CoT 응답을 필터링하였습니다.
- 각 프롬프트에 대해 여러 개의 응답을 샘플링한 후, 올바른 응답만 유지하였습니다.
- 최종적으로 약 60만 개(600k)의 추론 관련 학습 샘플을 수집하였습니다.
2) 비추론 데이터 (Non-Reasoning Data)
- 쓰기(writing), 사실 기반 QA(factual QA), 자기 인식(self-cognition), 번역(translation)과 같은 비추론 데이터도 포함하였습니다.
- 이를 위해 DeepSeek-V3의 기존 SFT 데이터셋을 재사용하였습니다.
- 일부 비추론 작업에서는
- DeepSeek-V3 모델을 활용하여 CoT를 생성한 후 답변을 생성하도록 프롬팅(prompting)하였습니다.
- 하지만, 단순한 질의(예: "안녕하세요")에는 CoT 없이 직접 답변을 제공하였습니다.
- 최종적으로 약 20만 개(200k)의 비추론 데이터 샘플을 수집하였습니다.
3) 모델 미세 조정
- 위에서 수집한 약 80만 개(800k)의 학습 샘플을 활용하여,
- DeepSeek-V3-Base 모델을 2 에포크(epoch) 동안 미세 조정하였습니다.
2.3.4. 모든 시나리오를 위한 강화 학습 (Reinforcement Learning for all Scenarios)
모델을 인간의 선호도(human preference)에 더욱 정렬시키기 위해,
- 추가적인 강화 학습 단계를 도입하여, 모델의 "유용성(helpfulness)"과 "무해성(harmlessness)"을 개선하는 것을 목표로 하였습니다.
추론 데이터(reasoning data)에 대해서는,
- DeepSeek-R1-Zero에서 사용된 것과 동일한 규칙 기반 보상(rule-based rewards)을 활용하여
- 수학, 코딩, 논리적 추론 등의 학습 과정을 안내하였습니다.
일반적인 데이터(general data)에 대해서는,
- 보상 모델(reward models)을 적용하여 복잡하고 미묘한 시나리오에서 인간의 선호도를 반영하였습니다.
2.4. 증류(Distillation): 작은 모델에 추론 능력 부여하기
더 작은 모델들도 DeepSeek-R1과 같은 추론 능력을 갖추도록 하기 위해,
우리는 DeepSeek-R1을 활용하여 생성한 80만 개(800k) 샘플을 사용하여
Qwen(Qwen, 2024b) 및 Llama(AI@Meta, 2024)와 같은 오픈 소스 모델을 직접 미세 조정(fine-tune)하였습니다.
이전 섹션 §2.3.3에서 설명한 바와 같이,
이러한 단순한 증류(distillation) 방식만으로도 작은 모델의 추론 능력이 상당히 향상됨을 확인할 수 있었습니다.
사용된 베이스 모델(Base Models)
우리가 증류에 사용한 기본 모델(base models)은 다음과 같습니다:
- Qwen2.5-Math-1.5B
- Qwen2.5-Math-7B
- Qwen2.5-14B
- Qwen2.5-32B
- Llama-3.1-8B
- Llama-3.3-70B-Instruct
특히, Llama-3.3 모델을 선택한 이유는,
- Llama-3.1보다 약간 더 뛰어난 추론 능력(reasoning capability)을 가지고 있기 때문입니다.
증류 모델(Distilled Models)의 학습 방식
- 증류된 모델들은 오직 감독 학습(SFT, Supervised Fine-Tuning)만 적용하였으며,
- 강화 학습(RL) 단계는 포함하지 않았습니다.
사실, 강화 학습을 추가하면 모델 성능이 크게 향상될 수 있지만,
- 이번 연구의 주요 목표는 증류 기법(distillation technique)의 효과를 입증하는 것이므로,
- 강화 학습을 포함하는 실험은 향후 연구 커뮤니티에서 추가로 탐색할 수 있도록 남겨 두었습니다.
3. 실험 (Experiment)
벤치마크 (Benchmarks)
모델을 평가하기 위해 다음과 같은 벤치마크 데이터셋을 사용하였습니다:
- MMLU (Hendrycks et al., 2020)
- MMLU-Redux (Gema et al., 2024)
- MMLU-Pro (Wang et al., 2024)
- C-Eval (Huang et al., 2023)
- CMMLU (Li et al., 2023)
- IFEval (Zhou et al., 2023)
- FRAMES (Krishna et al., 2024)
- GPQA Diamond (Rein et al., 2023)
- SimpleQA (OpenAI, 2024c)
- C-SimpleQA (He et al., 2024)
- SWE-Bench Verified (OpenAI, 2024d)
- Aider 1
- LiveCodeBench (Jain et al., 2024) (2024년 8월 ~ 2025년 1월 데이터)
- Codeforces 2
- 중국 전국 고등학교 수학 올림피아드 (CNMO 2024)
- 미국 초청 수학 경시대회 (AIME 2024, MAA 2024)
추가적으로, 열린 질문(open-ended generation tasks)에 대한 평가를 수행하기 위해,
- LLM(대형 언어 모델)을 심사관(judges)으로 활용하는 평가 방법을 적용하였습니다.
- AlpacaEval 2.0 (Dubois et al., 2024)
- Arena-Hard (Li et al., 2024)
이러한 열린 질문 평가(open-ended evaluation)에서는 GPT-4-Turbo-1106을 심사관으로 활용하여 쌍별 비교(pairwise comparisons)를 수행하였습니다.
- 길이 편향(length bias)을 방지하기 위해 오직 최종 요약(final summary)만 평가에 사용하였습니다.
증류된(distilled) 모델의 경우,
- AIME 2024, MATH-500, GPQA Diamond, Codeforces, LiveCodeBench에서 대표적인 결과를 보고(report)하였습니다.
평가 프롬프트 (Evaluation Prompts)
DeepSeek-V3의 설정을 따르며,
- MMLU, DROP, GPQA Diamond, SimpleQA 등의 표준 벤치마크는 simpleevals 프레임워크를 사용하여 평가하였습니다.
- MMLU-Redux의 경우,
- Zero-Eval 프롬프트 형식(Zero-Eval prompt format, Lin, 2024)을 사용하여 제로샷(zero-shot) 방식으로 평가하였습니다.
- MMLU-Pro, C-Eval, CLUE-WSC의 경우,
- 기존 프롬프트가 few-shot 설정이므로, 이를 제로샷 설정으로 약간 수정하여 평가하였습니다.
- few-shot CoT(CoT in few-shot)이 DeepSeek-R1의 성능을 저하시킬 가능성이 있기 때문입니다.
기타 데이터셋은 기본 제공된(original) 평가 프로토콜을 그대로 따랐습니다.
코드 및 수학 벤치마크의 경우:
- HumanEval-Mul 데이터셋을 사용하였으며, 이는 다음과 같은 8개의 주요 프로그래밍 언어를 포함합니다:
- Python, Java, C++, C#, JavaScript, TypeScript, PHP, Bash
- LiveCodeBench 데이터는 2024년 8월 ~ 2025년 1월까지 수집된 데이터를 기반으로 CoT 형식으로 평가하였습니다.
- Codeforces 데이터셋은
- 10개의 Div.2 대회에서 출제된 문제들과 전문가가 제작한 테스트 케이스(expert-crafted test cases)를 기반으로 평가하였습니다.
- 평가 후, 예상 등급(expected ratings)과 참가자 비율(percentages of competitors)을 계산하였습니다.
- SWE-Bench Verified 결과는
- 에이전트리스(agentless) 프레임워크(Xia et al., 2024)를 통해 평가하였습니다.
- AIDER 관련 벤치마크는 "diff" 형식을 사용하여 측정하였습니다.
DeepSeek-R1의 출력은 각 벤치마크에서 최대 32,768 토큰으로 제한하였습니다.
베이스라인 모델 (Baselines)
DeepSeek-R1의 성능을 비교하기 위해,
다음과 같은 강력한 기준 모델(baselines)과 종합적인 비교 평가를 수행하였습니다:
- DeepSeek-V3
- Claude-Sonnet-3.5-1022
- GPT-4o-0513
- OpenAI-o1-mini
- OpenAI-o1-1217
특히, 중국 본토에서는 OpenAI-o1-1217 API 접근이 어렵기 때문에,
- 해당 모델의 성능은 공식 보고서(official reports)를 기반으로 평가하였습니다.
증류된 모델(distilled models)의 경우,
- 오픈 소스 모델인 QwQ-32B-Preview(Qwen, 2024a)와 비교하였습니다.
평가 설정 (Evaluation Setup)
모든 모델에 대해 최대 생성 길이(maximum generation length)를 32,768 토큰으로 설정하였습니다.
우리는 긴 출력(long-output) 추론 모델을 평가할 때 "탐욕적 디코딩(greedy decoding)"을 사용하면
- 반복률(repetition rate)이 높아지고,
- 체크포인트 간 변동성이 증가한다는 점을 발견하였습니다.
따라서, 기본 평가 방법을 pass@𝑘 평가(pass@𝑘 evaluation)로 설정하였으며,
- pass@1 점수(pass@1)를 보고할 때는 non-zero temperature(비영점 온도)로 평가를 진행하였습니다.
구체적인 설정:
- 샘플링 온도(sampling temperature): 0.6
- Top-𝑝 값: 0.95
- 각 질문당 𝑘개의 응답을 생성 (보통 4~64개, 테스트 세트 크기에 따라 다름)
- pass@1 점수(pass@1)는 다음과 같이 계산됩니다:

- 여기서 pip_i는 ii번째 응답이 정답일 확률을 나타냅니다.
- 이러한 방식은 더 신뢰할 수 있는 성능 추정값(performance estimates)을 제공합니다.
특히, AIME 2024 평가에서는
- 다수결 투표(majority voting) 결과(consensus results)를 추가로 보고하였으며,
- 64개의 샘플을 사용하여 cons@64 점수를 계산하였습니다. (Wang et al., 2022)

3.1. DeepSeek-R1 평가 (DeepSeek-R1 Evaluation)
교육 지향 지식 벤치마크에서의 성능 (Education-Oriented Knowledge Benchmarks)
- MMLU, MMLU-Pro, GPQA Diamond와 같은 교육 지향 지식 벤치마크에서,
- DeepSeek-R1은 DeepSeek-V3보다 뛰어난 성능을 보였습니다.
- 이러한 개선은 주로 STEM 관련 질문에서의 정확도 향상 덕분이며,
- 대규모 강화 학습(Large-Scale Reinforcement Learning)을 통해 상당한 성능 향상을 이루었습니다.
- FRAMES (장문 의존 QA 태스크)에서도 DeepSeek-R1은 뛰어난 성능을 보였으며,
- 강력한 문서 분석(Document Analysis) 능력을 입증하였습니다.
이는 AI 기반 검색(Search) 및 데이터 분석(Data Analysis) 분야에서 추론 모델의 가능성을 보여줍니다.
사실 기반 벤치마크에서의 성능 (Fact-Based Benchmarks)
- SimpleQA 벤치마크에서 DeepSeek-R1은 DeepSeek-V3보다 우수한 성능을 보이며,
- 사실 기반 질의응답(Fact-Based QA) 처리 능력을 입증하였습니다.
- 유사한 경향이 OpenAI-o1이 GPT-4o를 능가하는 경우에서도 나타났습니다.
- 그러나, DeepSeek-R1은 중국어 SimpleQA 벤치마크(Chinese SimpleQA)에서 DeepSeek-V3보다 낮은 성능을 기록하였습니다.
- 이는 안전성 강화 학습(Safety RL) 이후, 특정 질의에 대한 응답을 거부하는 경향 때문입니다.
안전성 RL을 적용하지 않을 경우, 정확도가 70% 이상으로 향상될 가능성이 있습니다.
형식 지시 준수 평가 (IF-Eval: Instruction Following Evaluation)
- DeepSeek-R1은 IF-Eval 벤치마크에서도 우수한 성능을 보였습니다.
- 이 벤치마크는 모델이 형식 지침(format instructions)을 얼마나 잘 따를 수 있는지를 평가하는데,
- 최종 SFT(Supervised Fine-Tuning) 및 RL 훈련의 마지막 단계에서 포함된 "지시 준수 데이터(Instruction-Following Data)"가 성능 향상에 기여한 것으로 보입니다.
창작 및 자유형 질의응답 성능 (Creative Writing & Open-Domain QA)
- AlpacaEval 2.0 및 ArenaHard 평가에서도 DeepSeek-R1은 뛰어난 성능을 보였습니다.
- 이는 DeepSeek-R1이 창작(Writing) 및 자유형 질의응답(Open-Domain QA) 태스크에서도 강점을 보임을 시사합니다.
- DeepSeek-V3보다 현저히 뛰어난 성능을 기록했으며,
- 대규모 RL이 모델의 추론 능력뿐만 아니라 다양한 도메인에서의 성능까지도 향상시킬 수 있음을 보여줍니다.
- 또한, DeepSeek-R1의 요약 길이는 평균적으로 다음과 같이 측정되었습니다.
- ArenaHard: 평균 689 토큰
- AlpacaEval 2.0: 평균 2,218 문자
- 이는 GPT 기반 평가(GPT-Based Evaluation)에서 발생할 수 있는 "길이 편향(Length Bias)"을 피할 수 있도록 학습되었음을 보여주며,
- 다양한 태스크에서의 강건함(Robustness)을 더욱 강화하는 요소가 되었습니다.
수학 및 코딩 태스크에서의 성능 (Math & Coding Benchmarks)
- 수학 관련 태스크에서, DeepSeek-R1은 OpenAI-o1-1217과 동등한 성능을 보였으며,
- 다른 모델들을 큰 차이로 앞질렀습니다.
- 코딩 알고리즘(Coding Algorithm) 태스크에서도,
- LiveCodeBench 및 Codeforces 벤치마크에서 추론 중심 모델(Reasoning-Focused Models)이 우수한 성능을 기록하는 경향을 보였습니다.
- 엔지니어링 중심 코딩 태스크(Engineering-Oriented Coding Tasks)에서,
- Aider 태스크에서는 OpenAI-o1-1217이 DeepSeek-R1보다 더 우수한 성능을 보였지만,
- SWE Verified 벤치마크에서는 두 모델이 유사한 성능을 기록하였습니다.
향후 발전 가능성 (Future Improvements)
- DeepSeek-R1의 엔지니어링 성능(Engineering Performance)은 향후 개선될 가능성이 높다고 예상됩니다.
- 현재 엔지니어링 관련 강화 학습 데이터(RL Training Data)가 제한적인 상태이며,
- 다음 버전에서는 이를 확장하여 더욱 향상된 성능을 기대할 수 있습니다.
3.2. 증류 모델 평가 (Distilled Model Evaluation)
테이블 5: DeepSeek-R1 증류 모델과 기타 비교 가능한 모델의 성능 비교

DeepSeek-R1 증류 모델의 효과 분석
Table 5에서 볼 수 있듯이,
- DeepSeek-R1의 출력을 단순히 증류(distillation)하는 것만으로도,
- 효율적인 DeepSeek-R1-7B 모델 (즉, DeepSeek-R1-Distill-Qwen-7B)이
- GPT-4o-0513과 같은 비추론(non-reasoning) 모델을 모든 벤치마크에서 능가(outperform)하였습니다.
또한,
- DeepSeek-R1-14B 모델은 QwQ-32B-Preview를 모든 평가 지표에서 뛰어넘었습니다.
- DeepSeek-R1-32B 및 DeepSeek-R1-70B 모델은 대부분의 벤치마크에서 OpenAI-o1-mini를 크게 초월(significantly exceed)하였습니다.
이러한 결과는 증류(distillation)의 강력한 가능성(strong potential)을 입증합니다.
4. 논의 (Discussion)
4.1. 증류(Distillation) vs. 강화 학습(Reinforcement Learning, RL)
실험 개요
- 3.2절에서, DeepSeek-R1을 증류(distilling)하면 작은 모델(small model)도 매우 뛰어난 성능을 달성할 수 있음을 확인할 수 있었습니다.
- 하지만 한 가지 남은 질문은,
- 강화 학습(RL)을 대규모로 적용하면 증류 없이도 유사한 성능을 얻을 수 있는가? 하는 점입니다.
이를 확인하기 위해,
- Qwen-32B-Base 모델을 수학, 코딩, STEM 데이터로 10K 스텝 이상 대규모 RL 학습을 진행하여
- DeepSeek-R1-Zero-Qwen-32B를 생성하였습니다.

- RL 학습을 진행한 DeepSeek-R1-Zero-Qwen-32B 모델의 성능은 QwQ-32B-Preview와 비슷한 수준이었습니다.
- 하지만 증류된 DeepSeek-R1-Distill-Qwen-32B 모델은 모든 벤치마크에서 월등히 뛰어난 성능을 기록하였습니다.
결론 (Findings)
- 강력한 모델을 증류하여 작은 모델로 변환하는 방식이 매우 효과적입니다.
- 반면, 강화 학습(RL)만으로 작은 모델을 학습시키려면 엄청난 연산 자원이 필요하며,
- 그럼에도 불구하고 증류 모델과 같은 성능을 보장할 수 없습니다.
- 증류(Distillation)는 비용 효율적이고 효과적인 전략이지만,
- 지능의 한계를 넘어서기 위해서는 여전히 더 강력한 베이스 모델과 대규모 RL이 필요할 수 있습니다.
4.2. 실패한 시도들 (Unsuccessful Attempts)
DeepSeek-R1을 개발하는 과정에서 여러 가지 실패와 시행착오가 있었습니다.
이러한 경험을 공유함으로써, 향후 연구에 도움이 될 수 있도록 하려 합니다.
(단, 이러한 접근 방식이 반드시 효과적인 추론 모델을 개발할 수 없는 것은 아닙니다.)
1) 과정 보상 모델 (Process Reward Model, PRM)
PRM은 모델이 더 나은 추론 경로(reasoning path)를 찾을 수 있도록 안내하는 방법으로 제안된 방식입니다.
(Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023)
그러나, 실제 실험에서는 다음과 같은 세 가지 주요 문제점이 있었습니다.
- 일반적인 추론 과정에서 세밀한 단계를 명확히 정의하는 것이 어렵습니다.
- 현재 중간 단계가 올바른지 여부를 판단하는 것도 어려운 과제입니다.
- 자동 주석(annotation)은 만족스러운 결과를 제공하지 못하며,
- 수동 주석(manual annotation)은 대규모로 확장하는 것이 어렵습니다.
- 모델 기반 PRM을 도입하면, 필연적으로 "보상 해킹(Reward Hacking)" 문제가 발생합니다.
- (Gao et al., 2022)
- 또한, 보상 모델을 재훈련하려면 추가적인 학습 리소스가 필요하며, 전체 훈련 파이프라인이 더욱 복잡해집니다.
2) 몬테카를로 트리 탐색 (Monte Carlo Tree Search, MCTS)
MCTS는 AlphaGo (Silver et al., 2017b) 및 AlphaZero (Silver et al., 2017a)의 아이디어에서 영감을 얻어,
추론 중 계산량을 확장할 수 있도록(test-time compute scalability) 모델을 개선하려는 접근 방식입니다.
MCTS 방식은 문제를 여러 개의 작은 부분으로 나누고, 해결 공간을 체계적으로 탐색하는 기법입니다.
- 이를 위해 모델이 특정 추론 단계에 해당하는 태그(tags)를 생성하도록 프롬프트(prompt)를 설계하였습니다.
- 훈련 과정에서는,
- MCTS를 활용하여 사전 학습된 가치 모델(value model)에 의해 탐색을 진행하고,
- 결과적으로 생성된 질문-답변 쌍을 사용하여 액터 모델(actor model)과 가치 모델(value model)을 함께 훈련하는 방식으로 반복 학습(iterative refinement)을 수행하였습니다.
MCTS 방식의 문제점
그러나, 이 접근 방식은 확장성 문제로 인해 어려움을 겪었습니다.
- 검색 공간(Search Space) 문제
- 체스(Chess)와 달리, 토큰 단위 생성(token generation)은 훨씬 더 거대한 탐색 공간을 필요로 합니다.
- 이를 해결하기 위해, 각 노드의 최대 확장 제한(max extension limit)을 설정하였지만,
- 그 결과 모델이 지역 최적점(local optima)에 갇히는 현상이 발생하였습니다.
- 가치 모델(Value Model)의 한계
- 가치 모델의 품질이 전체 생성 과정의 품질에 직접적인 영향을 미치며,
- 각 탐색 단계에서 올바른 방향을 제시하는 것이 중요합니다.
- 하지만, 세밀한 가치 모델(fine-grained value model)을 학습하는 것은 본질적으로 매우 어려운 작업이며,
- 결국 모델이 반복적으로 성능을 개선하는 것이 어려웠습니다.
결론 (Summary)
✅ PRM
- 보상 모델을 통해 모델의 추론 과정을 유도하려 했지만,
- 보상 해킹 문제와 높은 계산 비용으로 인해 효과가 제한적이었음.
✅ MCTS
- AlphaGo와 유사한 방식으로 추론 문제를 해결하려 했지만,
- 토큰 생성의 높은 검색 공간과 가치 모델 학습의 어려움으로 인해 성공하지 못함.
5. 결론, 한계점 및 향후 연구 방향 (Conclusion, Limitations, and Future Work)
5.1. 결론 (Conclusion)
이번 연구에서는 강화 학습(RL)을 통해 모델의 추론 능력을 향상시키는 과정을 공유하였습니다.
- DeepSeek-R1-Zero
- 콜드 스타트 데이터 없이 순수한 RL 학습을 진행한 모델이며,
- 다양한 태스크에서 강력한 성능을 달성하였습니다.
- DeepSeek-R1
- 콜드 스타트 데이터를 활용하고, 반복적인 RL 미세 조정을 적용한 모델입니다.
- 결과적으로, 다양한 태스크에서 OpenAI-o1-1217과 유사한 성능을 달성하였습니다.
또한, 추론 능력을 작은 밀집 모델(Small Dense Models)로 증류(Distillation)하는 연구를 수행하였습니다.
- DeepSeek-R1을 교사 모델(Teacher Model)로 활용하여 80만 개(800K) 훈련 샘플을 생성하였으며,
- 이를 활용해 여러 개의 작은 밀집 모델을 미세 조정(Fine-Tune)하였습니다.
그 결과,
- DeepSeek-R1-Distill-Qwen-1.5B는 GPT-4o 및 Claude-3.5-Sonnet을 수학 벤치마크에서 능가하는 성과를 기록하였습니다.
- AIME 2024에서 28.9%, MATH-500에서 83.9%를 기록
- 기타 증류된 밀집 모델들도 인상적인 결과를 보였으며,
동일한 체크포인트를 기반으로 학습된 다른 인스트럭션 튜닝 모델(Instruction-Tuned Models)보다 훨씬 뛰어난 성능을 달성하였습니다.
5.2. 향후 연구 방향 (Future Research Directions)
향후 DeepSeek-R1의 연구는 다음과 같은 방향으로 발전할 계획입니다.
① 일반적 능력 향상 (General Capability)
- 현재 DeepSeek-R1은 DeepSeek-V3보다 일부 작업에서 성능이 부족합니다.
- 함수 호출(Function Calling)
- 멀티턴 대화(Multi-Turn Conversations)
- 복잡한 롤플레잉(Complex Role-Playing)
- JSON 형식 출력(JSON Output Generation)
- 향후 연구에서는 긴 체인 오브 싱킹(Long CoT)을 활용하여 이러한 태스크를 향상시키는 방법을 탐색할 예정입니다.
② 언어 혼합 문제 해결 (Language Mixing Issue)
- DeepSeek-R1은 현재 중국어(Chinese)와 영어(English) 최적화 모델입니다.
- 따라서, 다른 언어로 입력된 질의에 대해 모델이 영어로 응답하는 언어 혼합(Language Mixing) 문제가 발생할 수 있습니다.
- 예를 들어,
- 프랑스어나 스페인어로 된 질의에도 모델이 영어로 추론하고 응답하는 경향이 있음
- 향후 업데이트에서는 이러한 한계를 해결할 예정입니다.
③ 프롬프트 엔지니어링 최적화 (Prompt Engineering Optimization)
- 실험 결과, DeepSeek-R1은 프롬프트(prompt)에 민감하게 반응하는 경향이 있습니다.
- 특히, Few-Shot Prompting을 사용하면 성능이 꾸준히 저하되는 현상을 발견하였습니다.
- 따라서, 최적의 성능을 위해 사용자들에게 제로샷(Zero-Shot) 방식으로 문제를 직접 설명하고, 출력 형식을 명확히 지정하는 것을 권장합니다.
④ 소프트웨어 엔지니어링 태스크 개선 (Software Engineering Tasks Improvement)
- 강화 학습 과정에서 평가 시간이 길어지면 RL 학습 효율성이 저하됩니다.
- 이로 인해, 소프트웨어 엔지니어링 태스크에 대규모 RL이 광범위하게 적용되지 않았으며,
- DeepSeek-R1이 소프트웨어 엔지니어링 관련 벤치마크에서 DeepSeek-V3보다 큰 개선을 보이지 못한 이유가 되었습니다.
- 향후 연구에서는 다음과 같은 방안을 적용하여 성능을 개선할 계획입니다.
- 소프트웨어 엔지니어링 데이터를 기반으로 거부 샘플링(Rejection Sampling) 적용
- 강화 학습 과정에서 비동기 평가(Asynchronous Evaluations) 기법을 도입하여 학습 효율성 개선
요약
1. 서론 (Introduction)
- 최근 LLM(대형 언어 모델)의 빠른 발전과 함께, 추론 능력을 향상시키기 위한 후처리(Post-Training) 기법이 중요해짐
- OpenAI의 o1 시리즈 모델처럼 체인 오브 싱킹(CoT) 방식의 추론이 강력한 성능을 발휘함
- 하지만, 기존 연구들은 대부분 감독 학습(SFT, Supervised Fine-Tuning)에 의존
- DeepSeek-R1-Zero
- 순수한 강화 학습(RL)만으로 모델이 강력한 추론 능력을 획득할 수 있는지 탐구
- DeepSeek-R1
- 콜드 스타트 데이터와 다단계 RL을 활용하여 더욱 강력한 성능을 보이는 모델
- 결과적으로, DeepSeek-R1은 OpenAI-o1-1217과 유사한 성능을 달성
- 또한, DeepSeek-R1을 증류하여 작은 모델에도 강력한 추론 능력을 부여하는 연구를 수행
2. 접근 방법 (Approach)
2.1. 개요 (Overview)
- 기존 연구들은 대규모 감독 학습(SFT)에 의존하였으나, 강화 학습(RL)만으로도 강력한 추론 능력을 개발할 수 있음을 입증하려 함
- 두 가지 접근법을 실험
- DeepSeek-R1-Zero: 순수 RL 방식으로 학습된 모델
- DeepSeek-R1: 콜드 스타트 데이터 기반으로 사전 미세 조정 후 RL을 적용한 모델
2.2. DeepSeek-R1-Zero: 순수 RL 기반 학습
- 기존 모델 없이 순수 RL만으로 학습한 최초의 모델
- Group Relative Policy Optimization(GRPO) 기법을 활용하여 강화 학습 비용을 절감
- 보상 모델(Reward Model)은 정확도 보상(Accuracy Rewards)과 형식 보상(Format Rewards)으로 구성
2.3. DeepSeek-R1: 콜드 스타트 데이터 및 다단계 RL
- DeepSeek-R1-Zero의 한계를 극복하기 위해, 콜드 스타트 데이터를 활용한 모델 학습
- RL 훈련을 반복하여 모델의 추론 능력을 지속적으로 개선
- 비추론 태스크(Non-Reasoning Tasks)도 학습하여 실용적인 성능 향상
2.4. 증류(Distillation): 작은 모델에 추론 능력 이식
- DeepSeek-R1을 교사 모델로 활용하여 Qwen 및 Llama 기반 작은 모델들을 미세 조정
- 오직 감독 학습(SFT)만 적용했음에도 작은 모델에서도 강력한 추론 성능을 유지
3. 실험 (Experiment)
3.1. DeepSeek-R1 평가
- MMLU, GPQA Diamond, SimpleQA 등의 벤치마크에서 OpenAI-o1-1217과 유사한 성능 달성
- 수학(MATH-500), 코딩(LiveCodeBench), 논리 추론에서 기존 모델 대비 뛰어난 성능
3.2. 증류 모델 평가
- DeepSeek-R1-Distill-Qwen-32B 및 Llama-70B가 OpenAI-o1-mini를 초월하는 성능을 기록
- 특히, AIME 2024 및 MATH-500 벤치마크에서 GPT-4o 및 Claude 3.5-Sonnet보다 뛰어난 성과
4. 논의 (Discussion)
4.1. 증류 vs. 강화 학습
- 증류된 모델이 대규모 RL을 적용한 모델보다 뛰어난 성능을 보임
- 작은 모델에서 대규모 RL만으로 학습하는 것은 높은 연산 비용이 필요하며, 증류 모델보다 성능이 낮을 가능성이 큼
- 결론적으로, 증류는 비용 효율적이고 효과적인 방법이지만, 더 강력한 지능을 얻기 위해서는 대규모 RL도 여전히 필요
4.2. 실패한 시도들
- PRM(Process Reward Model): 보상 해킹 문제와 높은 연산 비용으로 인해 기대만큼 성능이 나오지 않음
- MCTS(Monte Carlo Tree Search): 토큰 생성 탐색 공간이 너무 커서 학습이 비효율적이었으며, 가치 모델(Value Model) 학습이 어려움
5. 결론, 한계점 및 향후 연구 방향 (Conclusion, Limitations, and Future Work)
5.1. 결론
- DeepSeek-R1-Zero는 순수 RL 학습만으로 강력한 추론 능력을 보유
- DeepSeek-R1은 콜드 스타트 데이터와 반복적 강화 학습을 통해 OpenAI-o1-1217과 유사한 성능 달성
- DeepSeek-R1을 활용하여 증류한 작은 모델들도 매우 우수한 성능을 보임
5.2. 향후 연구 방향
- ① 일반적 능력 향상 (General Capability): 함수 호출, 멀티턴 대화, JSON 출력 개선
- ② 언어 혼합 문제 해결 (Language Mixing Issue): 다른 언어 질의에서 자동으로 해당 언어로 응답하도록 개선
- ③ 프롬프트 최적화 (Prompt Engineering): Few-shot 프롬프팅 시 성능 저하 문제 해결
④ 소프트웨어 엔지니어링 태스크 개선: 비동기 평가 및 거부 샘플링을 통해 RL 훈련 효율성 향상
📌 최종 요약
🔹 DeepSeek-R1 연구의 핵심 기여
1️⃣ 순수 RL만으로도 LLM이 강력한 추론 능력을 학습할 수 있음을 입증 (DeepSeek-R1-Zero)
2️⃣ 콜드 스타트 데이터와 다단계 RL을 적용하면 더욱 강력한 성능을 달성 가능 (DeepSeek-R1)
3️⃣ 증류를 통해 작은 모델에서도 높은 성능을 유지할 수 있음 (DeepSeek-R1-Distill)
4️⃣ 대규모 RL이 증류보다 성능이 낮을 가능성이 있으며, 증류가 더 비용 효율적인 방식임
5️⃣ 향후 연구에서 다양한 태스크에 대한 최적화를 진행할 예정
'[AI] > 논문 리뷰' 카테고리의 다른 글
| 한국어 특화 모델 EXAONE 논문 리뷰 (2) | 2024.11.17 |
|---|---|
| 멀티 에이전트 Magentic-one 논문 리뷰 (2) | 2024.11.15 |