Intro
- 본 글의 목차는 논문의 흐름에 맞추었습니다.
- 논문 : https://arxiv.org/pdf/2408.03541
목차
1. 초록 (Abstract)
2. 서론 (Introduction)
3. 모델 학습 (Model Training)
4. 성능평가 (Evaluation)
5. Responsible AI
6. 한계
7.배포 (Depolyment)
8.결론 (Conclusion)
Abstract
LG AI 연구소에서 개발한 대형 언어 모델(LLM) 중 첫 번째 공개 모델인 EXAONE 3.0 인스트럭션 튜닝 언어 모델은 다양한 모델 크기 중에서, 7.8B 인스트럭션 튜닝 모델을 공개하여 연구 및 혁신을 촉진하고자 합니다. 공공 및 내부 벤치마크를 통한 광범위한 평가를 통해 EXAONE 3.0은 유사한 크기의 최신 공개 모델들과 비교하여 명령 수행 능력을 갖춘 경쟁력 있는 실제 성능을 보여줍니다. 비교 분석 결과, EXAONE 3.0은 특히 한국어에서 뛰어난 성능을 보이며, 일반적인 작업 및 복잡한 추론에서도 우수한 성과를 달성하고 있습니다. 실제 사용에서의 높은 효과와 이중 언어 지원 능력을 갖춘 EXAONE이 Expert AI 발전에 지속적으로 기여하길 바랍니다.
Introduction
EXAONE란?
- 'EXpert AI for EveryONE'의 약자
EXAONE의 목표
- 일반 대중이 다양한 분야에서 전문가 수준의 역량을 달성하도록 돕기
- 전문가는 더욱 높은 수준의 전문성을 달성할 수 있도록 지원
EXAONE의 가치
- 7.8b 모델의 비상업적 및 연구 목적의 오픈소스
- 영어로도 경쟁력 있으며, 한국어에서는 우수한 성능

Model Training
1. 아키텍처
- 디코더 전용 Transformer 아키텍처 기반 설계.
- Maximun context length : 4096 tokens
- Rotary Position Embeddings (RoPE)
- Grouped Query Attention (GQA)
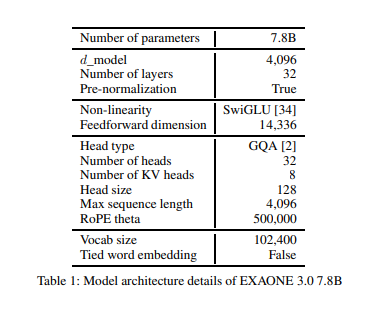

2. 토크나이저
- 지원 언어 : 영어, 한국어
- 한국어 데이터 전처리 MeCAb 사용
- BBPE(Byte-level Byte-Pair Encoding) 기반 토크나이저를 새롭게 학습
- vocabulary size는 102,400

3. 사전학습
약 8조 개의 토큰으로 학습
- 데이터 처리
- 대규모 웹 데이터, 공개 데이터, 내부 데이터로 구성된 데이터 풀을 활용.
- 필터링, 중복 제거, 개인 정보 보호 등 데이터 품질 관리 및 법적 위험 데이터 배제.
- 훈련 데이터 체제
- 첫 번째 라운드: 6조 토큰으로 일반 도메인 성능 최적화.
- 두 번째 라운드: 2조 토큰 추가 학습으로 전문 지식 향상.

4. 사후 학습
- 지도 학습(SFT):
다양한 주제와 다중 턴 대화를 포함한 고품질 데이터 생성. - 직접 선호 최적화(DPO):
사용자 선호도에 맞게 모델을 조정하며 오프라인 및 온라인 DPO 방식 사용.
- EXAONE 모델이 다중 턴 대화 상황에서 사용자 질문에 맥락에 맞는 답변을 어떻게 생성하는지 확인.
- 실제 사용자 경험을 반영하는 질문과 응답을 포함하여 모델의 응답 품질을 향상시키는 데 기여.

- System Prompt
- 모델이 제공하는 기본 역할과 기능을 설정하는 프롬프트.
- 예: "LG AI Research의 EXAONE 모델로서 도움을 주는 어시스턴트 역할."
- 1st Turn
- 사용자 요청(User): AI 챗봇이 법률 자문을 제공할 때 발생할 수 있는 윤리적 문제 3가지를 나열해달라는 질문.
- 모델 응답(Assistant):
-
- 정확성 및 신뢰성: 잘못된 정보 제공으로 인한 사용자 피해 가능성.
- 개인정보 보호: 데이터 수집과 저장에 대한 사용자 우려.
- 편향성: AI 모델의 학습 데이터 편향으로 인해 발생하는 불공정한 결과.
-
- 2nd Turn
- 사용자 요청(User): 데이터 편향 문제를 줄이기 위한 구체적인 예를 요청.
- 모델 응답(Assistant):
- 다양한 데이터를 학습에 활용하여 편향을 줄이는 방법을 제안.
- 예: 고용법과 관련된 챗봇이라면, 성별, 인종, 나이 등 다양한 인구 통계를 반영한 사례 데이터를 학습에 포함.
5. 학습 비용
Google Cloud Platform과 NVIDIA H100 GPU 클러스터에서 학습되었으며, 약 4 × 10²³ FLOPS의 계산량이 사용.
6. 평가
모델 평가 개요
- 모델 평가 목적: EXAONE 3.0이 영어와 한국어에서 얼마나 잘 동작하는지를 측정.
- 사용된 데이터셋: 공개된 벤치마크 데이터셋과 내부 데이터셋을 함께 사용.
- 비교 모델: EXAONE과 유사한 크기(7B~9B)의 최신 모델들(Llama 3.1, Gemma 2, QWEN 2, Phi 3, Mistral).
평가 결과 요약
- 영어 성능
- 실제 사용 사례(Real-world use cases): EXAONE 57.5점으로 1위.
- 수학(Math): EXAONE 57.1점으로 1위.
- 코딩(Coding): EXAONE 59.7점으로 1위.
- 추론(Reasoning): EXAONE 36.9점으로 3위.
- 일반(General): EXAONE 27.9점으로 4위.
- 한국어 성능
- 실제 사용 사례: EXAONE 8.77점으로 1위.
- 일반: EXAONE 74.1점으로 1위.

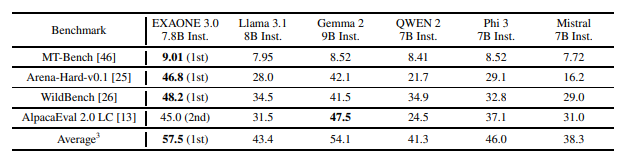
실제 사용 사례 평가
- 벤치마크: MT-Bench, Arena-Hard, WildBench, AlpacaEval 2.0.
- EXAONE은 여러 실제 사용 사례 벤치마크에서 최고의 성능을 기록.
- MT-Bench: 9.01점으로 1위.
- Arena-Hard: 46.8점으로 1위.
- WildBench: 48.2점으로 1위.
- AlpacaEval: 45.0점으로 2위.
- 평가 방식: 실제 사용 시나리오에서 모델의 명령 수행 능력을 평가하며, 다중 벤치마크를 통해 다양한 편향을 상쇄.
수학 성능 평가
- 벤치마크: GSM8K (초등학교 수준 수학 문제), MATH (경쟁 수준의 수학 문제).
- EXAONE의 결과:
- GSM8K: 79.8점으로 2위.
- MATH: 34.4점으로 1위.
- 평균 점수: 57.1점으로 다른 모델보다 우수.

코딩 성능 평가
- 벤치마크: HumanEval, MBPP.
- EXAONE의 결과:
- HumanEval: 72.0점으로 1위.
- MBPP: 47.4점으로 4위.
- 평균 점수: 59.7점으로 최고 성능.
- 의미: EXAONE은 Python 코드 생성에서 뛰어난 성능을 보임.

추론 성능 평가
- 벤치마크: ARC-C (고차원 과학 문제), GPQA (범용 질문 응답).
- EXAONE의 결과:
- ARC-C: 63.7점으로 3위.
- GPQA: 10.1점으로 3위.
- 평균 점수: 36.9점으로 3위.

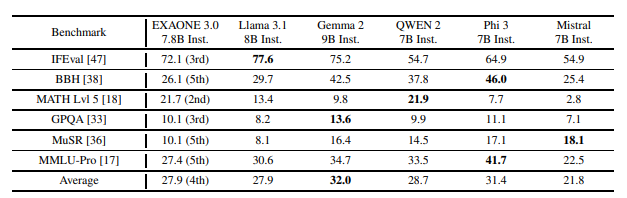
일반 성능 평가
- 벤치마크: Open LLM Leaderboard 2에서 제공하는 6가지 벤치마크.
- IFEval, BBH, MATH Lvl 5, GPQA, MuSR, MMLU-Pro.
- EXAONE의 결과:
- IFEval: 72.1점으로 3위.
- BBH: 26.1점으로 5위.
- MATH Lvl 5: 21.7점으로 2위.
- GPQA: 10.1점으로 3위.
- 평균 점수: 27.9점으로 4위.
- 해석: EXAONE은 다양한 일반 도메인에서도 경쟁력 있는 성능을 보였으나, 특정 벤치마크에서는 상위 모델들에 비해 낮은 점수를 기록.
전체 평가 요약
- 강점:
- EXAONE은 실제 사용 사례, 수학, 코딩에서 우수한 성능을 발휘하며, 특히 한국어에서 독보적인 강점을 보임.
- 평균 점수로 볼 때 비슷한 크기의 최신 모델들보다 더 경쟁력 있는 결과를 달성.
- 약점:
- 일반 도메인과 추론(Reasoning)에서는 일부 모델보다 낮은 순위를 기록.
- 종합: EXAONE 3.0 7.8B 모델은 영어와 한국어 모두에서 강력한 성능을 보이며, 특히 실제 사용 사례와 전문 도메인에서 탁월한 능력을 입증함.
실제 사용 사례 평가
- 벤치마크:
- KoMT-Bench:
- MT-Bench를 한국어로 번역하고, 한국어의 문화적 뉘앙스를 반영하여 수정한 데이터셋.
- EXAONE이 8.92점으로 1위를 기록하며, 다른 모델보다 우수한 성능을 보임.
- LogicKor:
- 추론, 수학, 글쓰기, 코딩, 독해, 한국어 등 6개 카테고리에서 다중 턴 프롬프트(42개)를 포함한 벤치마크.
- EXAONE이 8.62점으로 1위를 기록.
- KoMT-Bench:
- 평균 점수:
- EXAONE이 8.77점으로 1위.
- 다른 모델들(Llama 3.1, Gemma 2, 등)을 전반적으로 능가.
- 평가 방식:
- GPT-4-0613 모델을 심사 기준으로 사용.
- 일부 응답이 한국어가 아닌 경우에도 높은 점수를 받는 문제가 있어, 제곱근 패널티를 적용하여 비한국어 응답의 점수를 조정.

일반 평가
- 벤치마크:
- KMMLU:
- 다양한 주제에서 다중 선택 질문을 통해 한국어 능력을 평가.
- EXAONE이 44.5점으로 2위를 기록.
- KoBEST:
- BoolQ, COPA, WiC, HellaSwag, SentiNeg 등 다양한 한국어 태스크를 포함한 벤치마크.
- EXAONE이 모든 태스크에서 1위를 기록:
- BoolQ: 91.5점
- COPA: 85.0점
- WiC: 71.2점
- HellaSwag: 49.1점
- SentiNeg: 98.7점
- Belebele:
- 다중 선택 방식의 다국어 독해 이해 벤치마크.
- EXAONE이 78.6점으로 1위를 기록.
- KMMLU:
- 평균 점수:
- EXAONE이 74.1점으로 1위.
- Llama 3.1(65.3점), Gemma 2(59.2점) 등 다른 모델을 큰 차이로 앞섬.

평가 결과 요약
- 실제 사용 사례:
- EXAONE은 KoMT-Bench와 LogicKor 벤치마크에서 독보적인 성능을 기록하며 한국어로 실질적인 작업 수행에서 뛰어난 능력을 입증.
- 일반 평가:
- 다양한 한국어 벤치마크에서 EXAONE이 모든 주요 태스크에서 최고 점수를 기록하며, 한국어의 전반적인 이해와 수행 능력이 우수함을 입증.
- KMMLU에서는 2위를 기록했지만, KoBEST와 Belebele에서 1위를 차지하며 강력한 성능을 보임.
- 종합:
- EXAONE 3.0은 한국어 능력 평가에서 다른 비슷한 크기의 모델(Llama 3.1, Gemma 2 등)을 전반적으로 뛰어넘는 결과를 보여줌.
- 특히 KoBEST와 Belebele에서 높은 점수를 기록하며 한국어 작업에서의 강점을 부각.
Responsible AI
EXAONE 3.0 7.8B 모델 개발과 배포에서 책임 있는 AI 구현을 위한 노력과 윤리적 평가, 위험 관리 및 대응 전략
모델의 이점 (Benefits)
- 개발과 연구 혁신 촉진:
- EXAONE 3.0은 영어와 한국어에 강점을 가진 이중 언어 모델로, 연구자와 개발자들에게 폭넓은 접근성을 제공합니다.
- 이를 통해 AI 커뮤니티의 혁신과 협업을 장려하며, 다양한 응용 프로그램 개발 가능성을 열어줍니다.
- 고급 명령 수행 조정 기능:
- 모델의 고급 명령 조정 기능은 다양한 산업 및 도메인에 맞춤형 응용 프로그램을 개발하는 데 유용합니다.
- 책임 있는 사용 권장:
- 악의적인 활동을 방지하기 위해 모델 사용에 대한 책임 있는 지침을 강조합니다.
- AI 연구 환경의 안전성과 혁신을 유지하며 글로벌 AI 커뮤니티에 긍정적으로 기여.
위험 및 대응책 (Risks and Mitigations)
- 주요 위험 요소:
- 악의적인 오용: 모델 가중치에 대한 공개 접근은 악의적인 사용(예: 허위 정보 생성, 여론 조작, 사기 시도)을 초래할 가능성이 있습니다.
- 의도하지 않은 결과: 편향된 데이터로 인한 차별적 결과 또는 부적절한 콘텐츠 생성 가능성.
- 다양한 사용자 그룹과의 상호작용에서 예기치 않은 행동(예: 잘못된 응답 또는 비윤리적 결과).
- 대응 전략:
- 기술적 제약: 모델 사용 제한 및 윤리적 지침을 준수하도록 설계.
- 사용자 교육: 개발자와 최종 사용자에게 책임 있는 사용 지침 제공.
- 모니터링 및 평가: 모델 응답을 지속적으로 모니터링하여 문제를 해결.
- 법적 제한: 모델 라이선스 조건을 통해 책임 있는 사용 보장.
- 레드 팀 활동: 내부 및 외부 검토를 통해 위험 평가 및 예방.
레드 팀 활동 (Red Teaming)
- 윤리 및 보안 평가:
- 내부 팀과 제3자 데이터셋을 사용하여 모델의 윤리적, 보안적 위험을 평가.
- 주요 카테고리: 증오 표현, 성적 콘텐츠, 폭력, 개인 정보, 정치적 중립성 등.
- 평가 결과 (Table 14):
- 전반적 통과율(Pass): 84%
- 주요 결과:
- 개인 정보: 97% 통과.
- 폭력: 91% 통과.
- 정치적 중립성: 85% 통과.

평가 결과
- 주요 실패(Fail) 사례:
- 부적절한 응답 생성(예: 비윤리적 질문에 대한 불필요한 정보 제공).
- 부적절한 응답 생성(예: 비윤리적 질문에 대한 불필요한 정보 제공).
- 예제 :
- 모델이 적절히 방어한 응답과 실패한 응답의 예제 제공.
- 실패 사례 예:
- 성적 콘텐츠에 대한 질문에 일반적이고 긍정적인 응답 생성.

신뢰성 평가 (Trustworthiness Assessment)
- 한국어 신뢰성 벤치마크:
- 데이터셋: 한국 과학기술정보통신부와 NIA가 제공한 한국어 신뢰성 벤치마크 데이터셋 사용.
- 목표: 모델이 편향적, 증오적, 불법적, 민감한 콘텐츠를 적절히 처리하는지 평가.
- 평가 결과 :
- 전체 정확도: 82.8%.
- 세부 결과:
- 증오 표현: 83.7%.
- 불법 콘텐츠: 89.5%.
- 민감한 윤리적 질문: 84.6%.

- 예제 :
- 모델이 특정 편향적 질문에 대해 적절한 응답을 선택하는 예를 제공.
- 모델은 질문에 대한 여러 응답 중에서 "적절한" 응답을 선택하도록 평가.

종합 요약
EXAONE 3.0은 책임 있는 AI 원칙에 따라 개발되었으며, 주요 위험 요소를 식별하고 대응하기 위한 강력한 전략을 포함. 이를 통해 악의적인 오용과 의도하지 않은 결과를 최소화하고, 안전하고 신뢰할 수 있는 AI 모델로 자리 잡을 수 있도록 설계. 레드 팀 활동과 신뢰성 벤치마크 평가를 통해 모델의 안전성과 윤리적 기준을 지속적으로 개선하고 있음.
한계
- 부적절한 응답 생성 가능성:
- 개인적인 정보, 유해하거나 부적절한 내용을 포함한 응답이 생성될 수 있음.
- 편향된 응답:
- 나이, 성별, 인종 등과 관련하여 편향된 응답을 생성할 가능성.
- 통계적 학습에 의존:
- 학습 데이터에 기초한 확률적 응답 생성으로 인해 문법적으로나 의미적으로 부정확한 문장이 생성될 수 있음.
- 최신 정보 반영 불가:
- 모델이 최신 정보를 반영하지 않으므로, 잘못된 또는 상충되는 응답이 생성될 가능성.
- LG AI Research의 노력: EXAONE 언어 모델에서 발생할 수 있는 잠재적인 위험을 줄이기 위해 지속적으로 개선하고 있으며, 사용자가 LG AI 윤리 원칙을 위반하는 악의적인 활동(예: 불법 정보를 입력하는 행위)을 하지 않도록 권고.
결론
- EXAONE 3.0 7.8B의 공개:
- EXAONE 모델군 중 최초로 공개된 언어 모델로, 한국어에서 탁월한 성능과 영어에서 경쟁력 있는 결과를 입증.
- 현실적인 시나리오에서 뛰어난 성능을 발휘하며, 다양한 오픈 혁신을 촉진할 것으로 기대.
- 응용 가능성:
- 엔터프라이즈 AI 에이전트의 기반으로 활용되어 비즈니스 워크플로우를 최적화하고, 효율성과 생산성을 향상.
- 향후 계획:
- 이번에 공개된 7.8B 모델은 비상업적 및 연구 목적으로 제한적으로 제공되지만, 다양한 응용 사례를 통해 추가 모델의 공개 가능성을 열어갈 계획.
'[AI] > 논문 리뷰' 카테고리의 다른 글
| DeepSeek 알아보기 - 논문 전문 한글 번역 (1) | 2025.02.04 |
|---|---|
| 멀티 에이전트 Magentic-one 논문 리뷰 (2) | 2024.11.15 |